Gemini 3.5 Flash: Pricing, Benchmarks & Whether to Upgrade
Last updated: May 20, 2026 — first-day, hands-on. Pricing and benchmarks all cite primary sources at the bottom. Read time: 7 minutes. What you’ll learn: the surprising new Flash pricing, how to access Gemini 3.5 Flash today, your first agentic prompt, the 5 jobs it’s worth paying 3× for, and when to stay on Gemini 3 Flash.
Google didn’t ship Gemini 3.2 Flash, or 3.3, or 3.4. At I/O 2026 they jumped straight to Gemini 3.5 Flash — and the headline isn’t speed or context, it’s that Flash isn’t cheap anymore. List price is now $1.50/M input + $9/M output, roughly 3× a Gemini 3 Flash call and 6× a 3.1 Flash-Lite call (Simon Willison’s pricing analysis).
In exchange Google is selling you a model that, by their own benchmarks, beats Gemini 3.1 Pro on most tasks and runs 4× faster than other frontier models (Google I/O 2026 announcement).
This is the 7-minute guide. Skip the keynote replay, run a prompt, and decide if it’s worth the price hike for your workload.
What is Gemini 3.5 Flash (60 seconds)
Gemini 3.5 Flash is Google’s new default for everything — Gemini app, AI Mode in Search, Google Antigravity, and the new Gemini Spark assistant all run on it (TechCrunch). It’s no longer positioned as “the cheap fast one”; Google’s framing is agent-tier: a model designed to run autonomously for hours, executing multi-step coding and research pipelines.
The headline specs:
- Model ID:
gemini-3.5-flash(per Simon Willison’sllm-gemini0.32 release) - Context window: 1,048,576 input tokens, 65,536 output max
- Knowledge cutoff: January 2026
- Modalities in: text, image, audio, video, document (100+ page reasoning)
- No computer use (worth knowing if you were planning to ditch Claude Computer Use)
- Pricing: $1.50/M input + $9/M output (Simon’s source: the public API surface)
What’s gone vs the rumored 3.2 Flash leak from May 5: the “cheaper than 3 Flash” angle. That was a preview model people glimpsed in AI Studio and assumed was the new mid-tier. Google instead skipped four version numbers and rebranded Flash as their agent flagship — at a price point that puts it closer to Claude Sonnet than to what Flash used to mean.
How to access it (1 minute)
1. Gemini app (consumer, default)
- https://gemini.google.com
- It’s already the default — no model picker needed. Open the app and the next message uses 3.5 Flash. The model picker shows three Gemini 3 options (3.1 Flash-Lite, 3.5 Flash, 3.1 Pro); 3.5 Flash is pre-selected for new conversations globally.
2. AI Studio (free playground)
- https://aistudio.google.com
- Model dropdown → Gemini 3.5 Flash (the model card explicitly says: “Our most intelligent model for sustained frontier performance in agentic and coding tasks.”)
- The URL will include
?model=gemini-3.5-flash - Free tier covers experimentation; rate-limited
3. Gemini API (production)
curl -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/gemini-3.5-flash:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [{
"parts": [{"text": "Plan and implement a CLI tool that converts a folder of markdown to a static blog."}]
}]
}'Get a key at https://aistudio.google.com/apikey.
For Python / Node, use the official google-genai SDK or Simon Willison’s llm-gemini 0.32 plugin which already shipped support for streaming reasoning tokens on this model.
Your first prompt (2 minutes)
The wrong way to try 3.5 Flash is to ask it “write me a haiku.” That’s a $0.01 test of a $9/M-output model. The right way is to push it on the thing Google actually retuned for: multi-step agentic execution.
Paste this into AI Studio with 3.5 Flash selected:
You are an autonomous coding agent. Plan, then execute.
Goal: Convert the following messy CSV into a clean SQLite schema with
proper types, indexes on every foreign-key field, and a seed file with
the data, with all the dirty-data issues fixed.
CSV:
order_id,customer_email,product_name,quantity,price_usd,order_date,status
1001,john@example.com,Wireless Mouse,2,29.99,2026-01-15,shipped
1002,JANE@EXAMPLE.COM,Mechanical Keyboard,1,89.50,01/16/2026,pending
1003,bob@example.com,USB Hub,,15.99,2026-01-17,
1004,sara@example.com,Wireless Mouse,3,$29.99,2026-1-18,SHIPPED
1005,john@example.com,Monitor Stand,1,45,2026/01/19,cancelled
1006,mike@example.com,USB Hub,1,15.99,2026-01-20,shipped
1007,JANE@EXAMPLE.COM,Webcam HD,1,79.00,Jan 21 2026,shipped
1008,bob@example.com,Mechanical Keyboard,1,89.5,2026-01-22,pending
Output, in order:
1. PLAN — bullet list of every step you'll do.
2. SCHEMA — CREATE TABLE statements with reasoning. Normalize customers
and products into their own tables with foreign keys.
3. SEED — INSERT statements with all dirty-data issues cleaned up
(emails lowercased, dates ISO-8601, prices as numbers, statuses
lowercased, missing values handled).
4. VERIFICATION — three SELECT queries that prove correctness.
5. WHAT I CAN'T VERIFY — any assumption you had to make and what
could break it.
Stop after section 5. No fluff.The CSV has eight rows of intentionally messy data: mixed-case emails, four different date formats, currency symbols on some prices but not others, missing quantity, missing status. It’s exactly the kind of thing you find when an Ops team hands you a “we exported the orders, can you make a dashboard.”
What 3.5 Flash actually did
I ran this in AI Studio at 10:33 AM on launch day. First thing it did before any output — stream its reasoning live. This is new in 3.5: structured thinking tokens before the answer. (It’s also why llm-gemini 0.32 shipped same-day with reasoning-token streaming support.)
Then section 1 — a 6-step plan, not a generic outline but specifically for this CSV:

Section 2 — three normalized tables (customers, products, orders) with PRAGMA foreign_keys = ON and FK indexes I asked for:

One thing I didn’t ask for that it did anyway: it kept price_usd on both products and orders (renaming the orders column to price_paid) — a historical price snapshot at purchase time. That’s a senior-engineer data-modeling pattern (so you can change product prices later without rewriting old orders). Nothing in my prompt said to do it; the model inferred the requirement.
Section 3 — INSERTs with inline annotations explaining each fix:
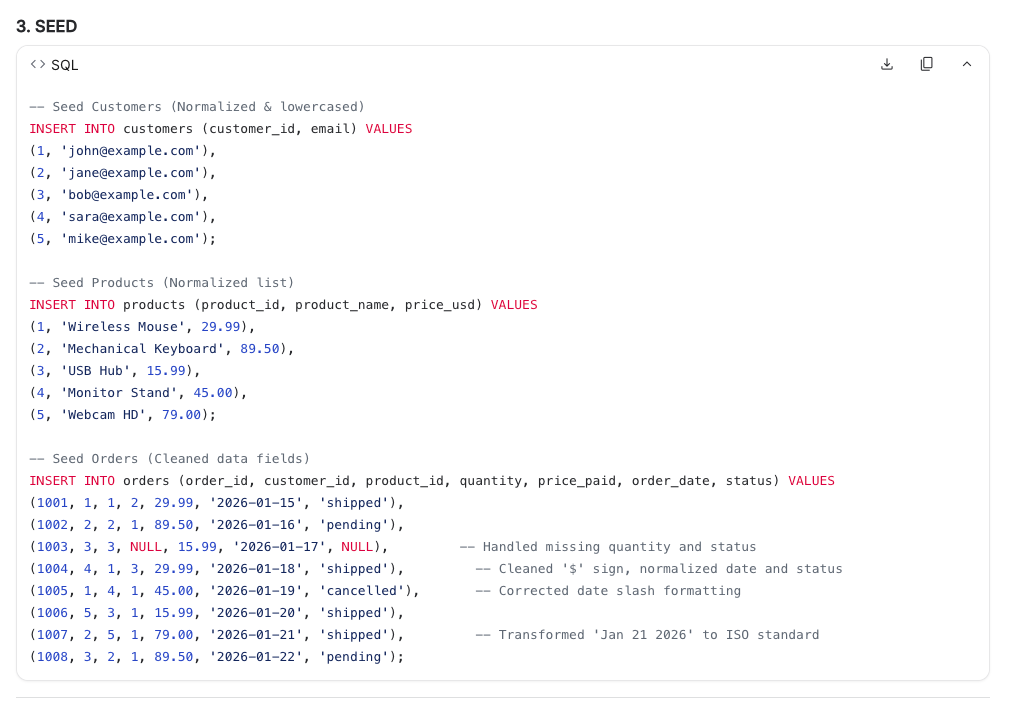
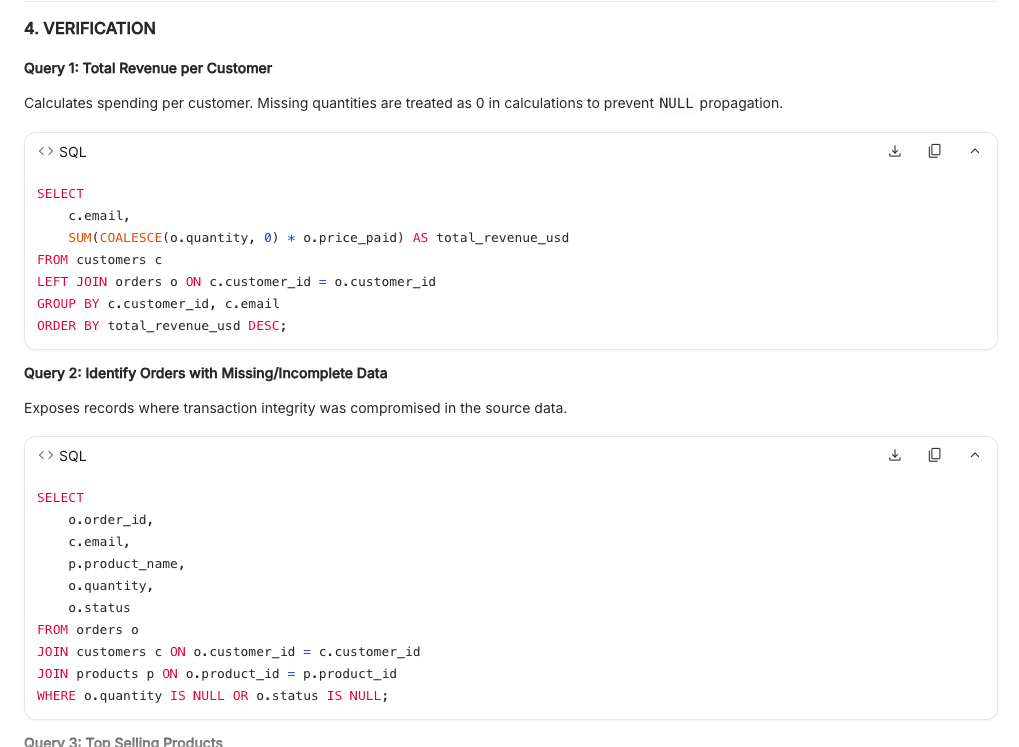
Section 4 — three verification queries. Query 1 wraps SUM(o.quantity) in COALESCE(o.quantity, 0) to stop a single NULL from poisoning a customer’s total. That’s the kind of detail a junior dev forgets and the data team finds in production a month later.
And the section I was most curious about — 5. What I Can’t Verify:
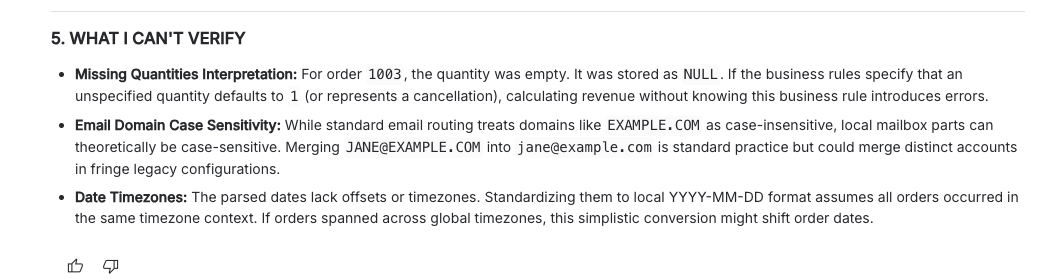
In text, the three caveats:
- Missing Quantities Interpretation — order 1003’s empty quantity was stored as NULL, but “if business rules specify that an unspecified quantity defaults to 1 (or represents a cancellation), calculating revenue without knowing this business rule introduces errors.”
- Email Domain Case Sensitivity — merging
JANE@EXAMPLE.COMintojane@example.comis “standard practice but could merge distinct accounts in fringe legacy configurations.” - Date Timezones — “The parsed dates lack offsets or timezones. If orders spanned across global timezones, this simplistic conversion might shift order dates.”
This is the test 3.5 Flash actually passed. Cheaper Flash variants — and most GPT-4-class models when run cheaply — will write a confident “everything looks good” or skip section 5 entirely. 3.5 Flash gave three caveats that are specifically the things a careful engineer would flag during code review: business-rule ambiguity, legacy compatibility, and timezone implicit assumptions.
That self-awareness is the entire reason this model is priced like Pro instead of like Flash. If you only ever ask it for chat responses, you’re paying 3× for nothing. If you’re orchestrating an agent loop where one wrong assumption goes unflagged for hours, the price suddenly makes sense.
Top 5 things it’s worth paying 3× for
These are the workloads where 3.5 Flash’s price actually pencils out vs staying on 3 Flash:
1. Multi-step agent loops
- Per Google: “runs autonomously for multiple hours, pauses to request human input at decision points”
- In a live I/O demo, agents spawned in parallel built components and assembled a full toy operating system
- If you’re orchestrating Cursor / Claude Code / Codex CLI–style flows, 3.5 Flash sits in the cost bracket of Sonnet but reaches further between human checkpoints
2. Coding pipelines (Terminal-Bench 2.1: 76.2%)
- Google’s own benchmark — Terminal-Bench 2.1 — has 3.5 Flash at 76.2%, MCP Atlas at 83.6% (source)
- The TechCrunch piece quotes Google’s CTO claiming 3.5 Flash “outperforms our latest frontier model, 3.1 Pro, on nearly all the benchmarks”
- This is Google saying: skip Pro, use this for code
3. Long-document reasoning (1M context, 100+ page docs)
- Context window unchanged at 1M input, but Google specifically highlights “100+ page document reasoning”
- Same use case as Claude with long PDFs, now with a model tuned to actually act on what it reads
4. Interactive UI/graphics generation
- 3.5 Flash is the engine behind the AI Mode in Search overhaul — interactive maps, infographics, SVGs
- Simon Willison’s SVG-pelican benchmark cost ~13¢ per generation (11 input + 14,403 output tokens) — actually viable for app-embedded image-driven UI
5. Drop-in upgrade for anyone on 3.1 Pro
- This is the strange one. Gemini 3.1 Pro Preview is $2/$12 per 1M (and $4/$18 above 200K context). 3.5 Flash is $1.50/$9 — actually cheaper than Pro — and Google’s own CTO says it beats 3.1 Pro on nearly all benchmarks, with 4× speed.
- If you’re paying for Pro today, the migration is literally one model-ID string change.
Gemini 3.5 Flash vs the alternatives
| Gemini 3.5 Flash | Gemini 3 Flash Preview | Gemini 3.1 Pro Preview | Claude Sonnet 4.6 | |
|---|---|---|---|---|
| Input / 1M | $1.50 | $0.50 (text/img/video), $1.00 (audio) | $2.00 (≤200K), $4.00 (>200K) | $3.00 |
| Output / 1M | $9.00 | $3.00 | $12.00 (≤200K), $18.00 (>200K) | $15.00 |
| Context in | 1,048,576 | 1M | 1M | 200K |
| Computer use | ❌ | ❌ | ❌ | ✅ |
| Speed claim | ”4× frontier” | Baseline | Slower | Comparable |
| Best for | Multi-hour agent loops, coding, long docs | Cheap volume | (Largely superseded by 3.5 Flash) | Computer use + careful reasoning |
All Gemini numbers from https://ai.google.dev/gemini-api/docs/pricing; Claude Sonnet 4.6 from Anthropic’s pricing page.
The real question this table answers: if you’re on Pro, downgrade to 3.5 Flash — yes, downgrade in name, but it’s actually cheaper and benchmarks higher. If you’re on 3 Flash for cost reasons, stay there — 3.5 Flash is not the sequel, it’s a different product at a different price point.
Pricing (30 seconds)
- Input: $1.50 / 1M tokens
- Output: $9.00 / 1M tokens
- Source: Confirmed on Google’s official pricing page at https://ai.google.dev/gemini-api/docs/pricing (also independently verified by Simon Willison’s first-day pricing analysis).
Simon Willison’s running an Artificial Analysis benchmark on it cost $1,551.60 — more than the 3.1 Pro Preview benchmark ($892.28). For high-volume API users, the price hike is real and material; budget accordingly.
Common errors + FAQ
Q: I used to write gemini-3-flash — what’s the new model ID?
A: gemini-3.5-flash. Note the dot — older Google APIs sometimes accept gemini-3-5-flash too, but the canonical string per Google’s llm-gemini plugin is gemini-3.5-flash.
Q: Does it support computer use? A: No. If you want Anthropic-style “let the model control my browser,” you’re still on Claude Sonnet 4.6.
Q: Can it call tools / functions? A: Yes — same tool-calling and grounding surface as Gemini 3 Flash. The MCP Atlas score (83.6%) suggests strong MCP compatibility specifically.
Q: Knowledge cutoff? A: January 2026 (per Simon Willison’s first-day API probe). For events after that, attach grounding or use Google Search integration.
Q: Should I migrate from Gemini 3 Flash? A: Only if you’re CPU-bound on agent / coding work. For pure throughput tasks (translation, summarization, bulk OCR), 3 Flash at 1/3 the price is still the right call. Test before you migrate.
Q: Where does Gemini Spark fit in? A: Spark is the product (24/7 personal AI assistant); 3.5 Flash is the model powering it. See our Gemini Spark tutorial for the full breakdown.
Q: And Gemini Omni Flash? A: Omni Flash is the video counterpart — same I/O wave, same Gemini family, optimized for video generation and conversational editing. See our Gemini Omni Flash tutorial for prompts and the comparison to Sora / Veo / Kling.
What to use it with
- For coding agents: Cursor, Cline, or Google’s brand-new Android CLI all support custom Gemini model IDs.
- For Python/Node prototyping: Simon Willison’s
llmtool withllm-gemini 0.32lets you stream reasoning tokens from the CLI in one line. - For RAG / grounding: native Search grounding works the same way as on 3 Flash.
Related tutorials
- Already live: 7 Minutes to Master Gemini Spark — the consumer-facing 24/7 agent running on 3.5 Flash
- Already live: 7 Minutes to Master Gemini Omni Flash — the video-gen sibling from the same I/O wave
- Coming this week: Android CLI for Claude Code & Codex (Google’s new dev tool, also unveiled at I/O 2026)
- Coming this week: 50 Best Gemini 3.5 Flash Agent Prompts
Sources
Every fact above traces back to one of these. Where I made a judgment call (e.g., “wait on Pro migration”), it’s my opinion; the data isn’t.
- Google’s official Gemini 3.5 announcement — https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-5/ — benchmarks, modalities, access points, agent positioning
- Simon Willison: “Gemini 3.5 Flash: more expensive, but Google plan to use it for everything” — https://simonwillison.net/2026/May/19/gemini-35-flash/ — exact pricing, model ID, context limits, knowledge cutoff, “no computer use” note, real-world benchmark cost
- Simon Willison:
llm-gemini0.32 release — https://simonwillison.net/2026/May/19/llm-gemini/ — canonical model ID string, streaming reasoning tokens support - TechCrunch: “With Gemini 3.5 Flash, Google bets its next AI wave on agents, not chatbots” — https://techcrunch.com/2026/05/19/with-gemini-3-5-flash-google-bets-its-next-ai-wave-on-agents-not-chatbots/ — Koray Kavukcuoglu quote on outperforming 3.1 Pro, “multiple hours of autonomous execution,” 4× / 12× speed claims, products using it
- Google Gemini API pricing page — https://ai.google.dev/gemini-api/docs/pricing — official $1.50/$9 confirmation; also where the 3 Flash Preview ($0.50/$3) and 3.1 Pro Preview ($2/$12 base, $4/$18 above 200K context) numbers in the comparison table come from