Cohere's Command A+ is open-weight, Apache 2.0, and runs agentic work on 2 H100s
Cohere released Command A+ as open weights under Apache 2.0 — a 218B sparse MoE with 25B active params that runs on two H100s (or one B200) at W4A4 quantization. It's built for agentic tasks, RAG, and 48 languages, with native citations. Here's why it matters if you need open weights you can actually self-host.
Cohere released Command A+ as an open-weight model under an Apache 2.0 license — its most capable model to date, and one aimed squarely at teams that need open weights they can host themselves. (Source: Cohere blog, 2026-05-20) For builders who can’t send data to a hosted API, the news is the license and the hardware floor, not just the benchmark scores.
Key facts:
- It is a 218B sparse MoE with 25B active parameters. Only the active params run per token, so it serves far cheaper than its total size suggests. (Source: Cohere blog, 2026-05-20)
- It runs on 2× NVIDIA H100s, or a single B200, both at W4A4 quantization.
- The license is Apache 2.0 — commercial use, no usage restrictions.
- The context window is 128K tokens in, 64K out.
- It handles text, images, and tool use as input.
- It supports 48 languages, up from 23 in earlier Command A versions.
- Weights are on Hugging Face in BF16, FP8, and W4A4 quantizations.
What actually shipped
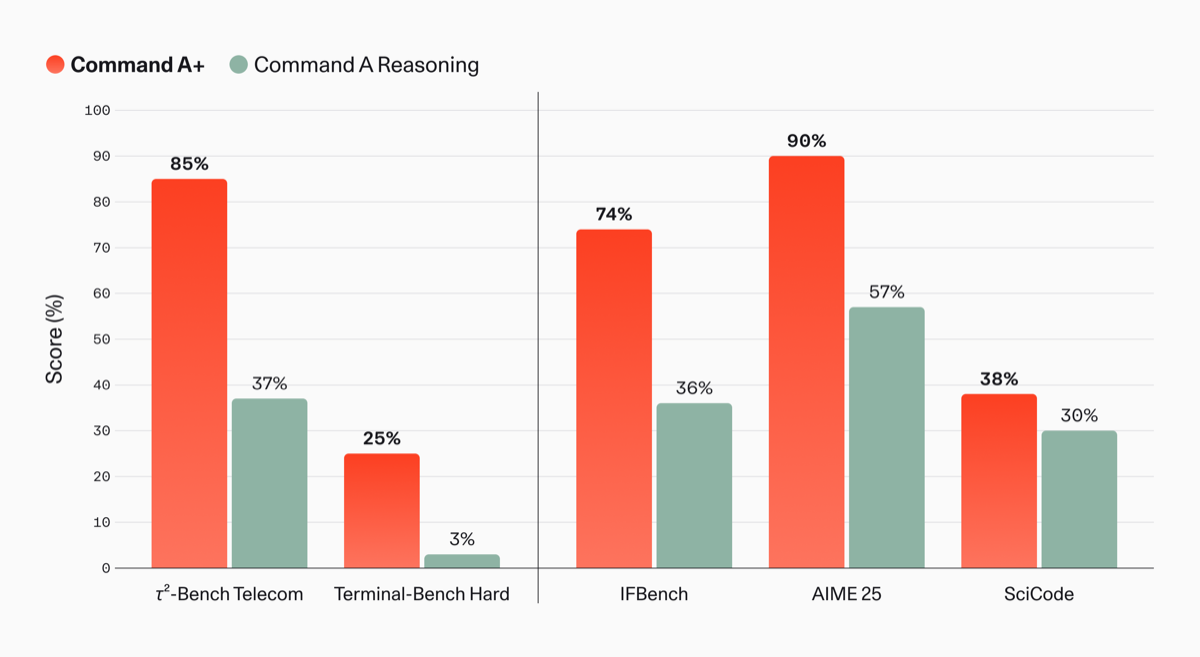
The jump over Cohere’s previous model is largest on agentic and tool-use tasks. On τ²-Bench Telecom, Command A+ scores 85% versus 37% for Command A Reasoning. On Terminal-Bench Hard, it goes from 3% to 25%. (Source: Cohere blog, 2026-05-20) On multimodal tests it posts 63% on MMMU Pro, 75.1% on MMMU, and 80.6% on MathVista. Its Artificial Analysis Intelligence Index sits at 37.
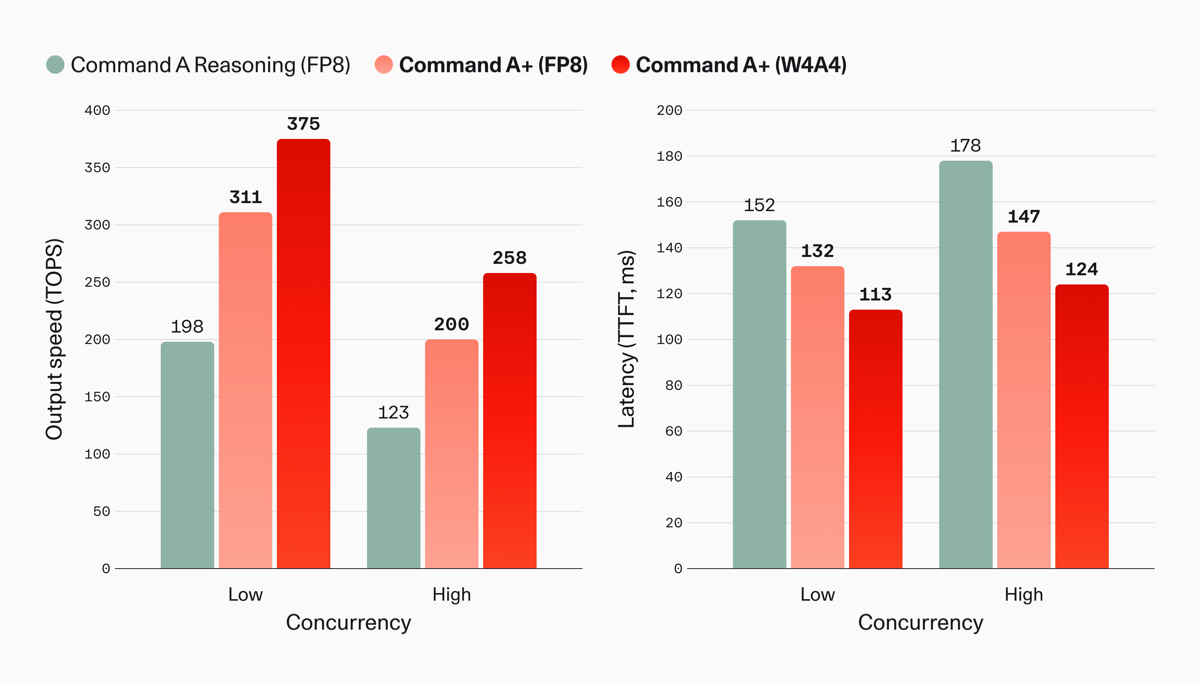
Speed got attention too. Cohere reports output throughput 63% faster than Command A Reasoning, a 17% cut in time-to-first-token, a further 47% boost from W4A4 quantization, and 1.5–1.6× from speculative decoding on top. The model keeps Cohere’s signature feature for RAG: native, inline citations in the output rather than a bolted-on retrieval step.
What this means if you need open weights
The story here is the deployment math. A 218B model usually implies an 8-GPU node. Command A+ at W4A4 fits on two H100s — hardware many teams already have — while only 25B params are active per token, so throughput stays high. Paired with Apache 2.0, that makes it one of the few frontier-adjacent open models you can legally run in an air-gapped or compliance-bound environment without renegotiating a license.
That puts it in direct competition with the open-weight coding and reasoning models builders have been self-hosting all year. If you’re standing up open weights locally, the workflow in our guide to running Qwen 3.6 for local coding carries over — quantization choice, GPU sizing, and serving all work the same way. And the open-weight watch on Qwen 3.7 and the Reasonix coding agent are the natural points of comparison when you’re choosing which open model to commit a deployment to.
The catch
Two H100s is a low floor for a 218B model, but it’s still a low floor, not a laptop — this is a server-class deploy, not an on-device model. The headline benchmark gains are measured against Cohere’s own prior model, not against the latest Qwen, DeepSeek, or Llama releases, so run your own head-to-head before assuming it leads the open field. And the most impressive scores are on agentic and enterprise-integration tasks; if your workload is plain single-turn chat, the gap over cheaper open models narrows.
Sources
- Introducing Command A+ — Cohere, 2026-05-20
- Cohere releases its most powerful AI model as open source — BetaKit, 2026-06-04
- Cohere open-sources its strongest model yet — The Decoder, 2026-06
Source: Cohere