Gemma 4 12B: Google's encoder-free open model runs text, image, and audio on a 16GB laptop
Google released Gemma 4 12B on June 3, 2026 — an Apache 2.0 multimodal model that drops its vision and audio encoders, handles text, images, and native audio, and fits on a 16GB consumer laptop. On Google's own benchmarks the 12B nearly matches the larger Gemma 4 26B. Here's what the encoder-free design changes for builders running local multimodal.
Google released Gemma 4 12B on June 3, 2026 — an open-weight multimodal model that handles text, images, and audio without any separate encoder modules. (Source: Google, 2026-06-03) The headline for builders: it fits on a 16GB consumer laptop and ships under Apache 2.0, so you can run and ship it commercially.
Key facts:
- The model has 12 billion parameters.
- License is Apache 2.0 — commercial use is permitted.
- It runs locally on a laptop with 16GB of RAM.
- It accepts text, images, and native audio in one model.
- It is encoder-free: the vision encoder is replaced by a 35M-parameter embedding module (a single matrix multiply plus positional embedding and norms), and the audio encoder is removed entirely — raw 16kHz audio is projected straight into the token space. (Source: Google, 2026-06-03)
- Weights are on Hugging Face and Kaggle, with day-one support for Ollama, LM Studio, llama.cpp, MLX, vLLM, SGLang, and Unsloth.

What the benchmarks show
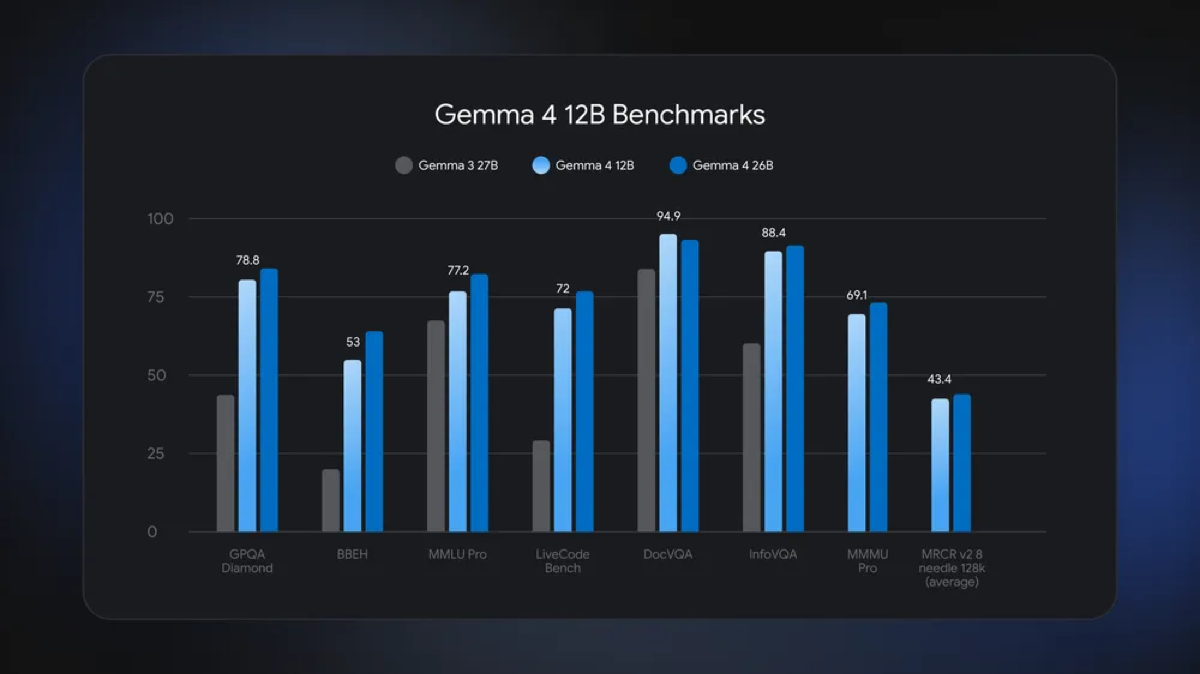
On Google’s own benchmark chart, the 12B model nearly matches the twice-as-large Gemma 4 26B and clearly beats the older Gemma 3 27B. The published Gemma 4 12B scores: GPQA Diamond 78.8, MMLU Pro 77.2, LiveCodeBench 72, DocVQA 94.9, InfoVQA 88.4, MMMU Pro 69.1, and BBEH 53. (Source: Google official benchmark chart, 2026-06-03)
One caveat worth reading correctly: the “video” capability is frame-plus-audio analysis, not native video encoding. Google’s demo parsed a 5-minute clip as 313 frames at one per second, plus the audio track — useful, but it samples frames rather than watching continuous motion. (Source: The Decoder, 2026-06-03)
What this means if you’re building local multimodal
The encoder-free design is the real story for builders, not the parameter count. A typical local multimodal stack runs a separate CLIP-style vision encoder and an audio encoder alongside the language model — more weights to load, more latency per request, more moving parts to quantize. Gemma 4 12B collapses those into the transformer, which is how a model that reads images and listens to audio still fits in 16GB.
That puts a genuinely multimodal model in reach of a single laptop and an Apache 2.0 license — no per-token cloud bill for vision or speech, and no licensing asterisk on shipping it. If you’re standing up a local vision-language pipeline, the same vLLM and Transformers toolchain in our guide to running NuExtract 3 locally applies directly to Gemma 4, and if you want a local-coding baseline to compare against, see running Qwen 3.6 locally for coding. For serving with tools, llama.cpp’s built-in tool calling covers the inference side.
The trade-off: a 12B encoder-free model is strong for its size, but it is not a frontier multimodal model. Check it against your actual image and audio tasks before retiring a larger or hosted setup — the win here is running multimodal at all on hardware you already own.
Sources
- Introducing Gemma 4 12B: a unified, encoder-free multimodal model — Google (The Keyword), 2026-06-03
- Google DeepMind’s Gemma 4 12B squeezes multimodal AI onto a laptop with just 16GB of RAM — The Decoder, 2026-06-03
- Google DeepMind releases Gemma 4 12B, an encoder-free multimodal model with native audio — MarkTechPost, 2026-06-03
Source: Google (The Keyword)