Claude Opus 4.8 is live — the 4 changes builders should actually care about (it is not the benchmark numbers)
Anthropic shipped Claude Opus 4.8 on May 28, 2026. The release announcement calls it “a modest but tangible improvement,” which is the rare honest framing of an LLM release.
But the benchmark numbers are not the story here. The story is four under-the-fold changes that re-shape how builders wire up Claude into real agent products. If you ship anything that touches the Anthropic API or Claude Code, this is what you need to do this week.
Key facts:
- Released: May 28, 2026 (Source: Anthropic announcement)
- Pricing: $5 / $25 per million tokens — unchanged from Opus 4.5, 4.6, 4.7
- Fast mode pricing: $10 / $50 per million — 3× cheaper than Opus 4.6/4.7’s $30 / $150
- Prompt cache minimum: 1,024 tokens — down from 4,096 on Opus 4.7
- Context: 1,000,000 tokens. Max output: 128,000 tokens. Both unchanged
- Agentic computer use (OSWorld-Verified): 83.4% — up from Opus 4.7’s 82.8%, ahead of GPT-5.5 (78.7%) and Gemini 3.1 Pro (76.2%)
- Agentic coding (SWE-Bench Pro): 69.2% — up from Opus 4.7’s 64.3% (Source: Anthropic announcement)
- New feature: Dynamic Workflows in Claude Code, runs hundreds of parallel subagents
- New feature: Effort control slider (high default, “extra”/“xhigh”, “max”) in claude.ai, Cowork, and Claude Code
- New API feature:
role: "system"entries accepted mid-conversation, preserves prompt cache
Opus 4.7 vs 4.8 at a glance
| Dimension | Opus 4.7 | Opus 4.8 | Delta |
|---|---|---|---|
| Base pricing (input / output, per 1M tokens) | $5 / $25 | $5 / $25 | — |
| Fast mode pricing (input / output, per 1M tokens) | $30 / $150 | $10 / $50 | 3× cheaper |
| Prompt cache minimum | 4,096 tokens | 1,024 tokens | 4× lower threshold |
| Knowledge cutoff | January 2026 | January 2026 | — |
| Context window | 1,000,000 | 1,000,000 | — |
| Max output | 128,000 | 128,000 | — |
Mid-conversation system messages | No | Yes | new |
| Effort control slider | No | high / extra / max | new |
| Dynamic Workflows in Claude Code | No | research preview | new |
| Agentic computer use (OSWorld-Verified) | 82.8% | 83.4% | small gain |
| Agentic coding (SWE-Bench Pro) | 64.3% | 69.2% | +4.9 pts |
| 4× less likely to allow unflagged code flaws | baseline | 4× better | honesty win |
The list-rate price card has not moved for four releases. Everything that did move is in the cache, fast mode, agentic features, and honesty rows. That’s the shape of this release.
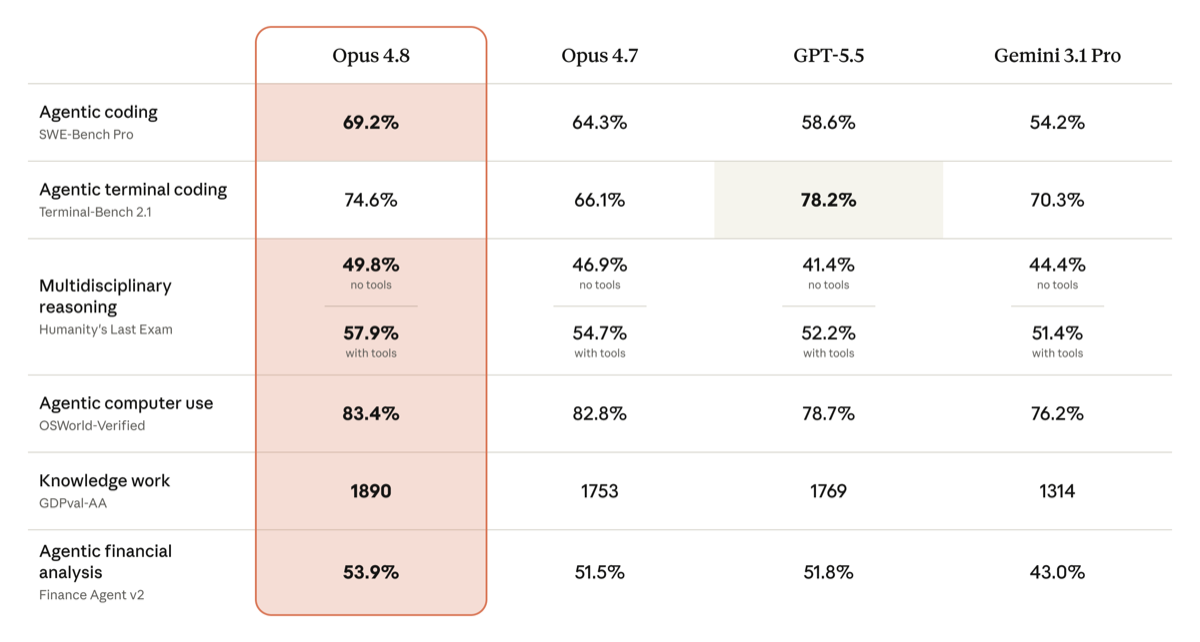
Opus 4.8 leads on agentic coding, computer use, reasoning, knowledge work, and financial analysis — but note GPT-5.5 still edges it on Terminal-Bench 2.1 (78.2% vs 74.6%). The gains are real, mostly single-digit. (Source: Anthropic announcement)
1. The prompt cache minimum dropped 4× — and this changes the math for small agents
This is the biggest under-reported change in the release.
On Opus 4.7, the minimum cacheable prompt length was 4,096 tokens. On Opus 4.8, it is 1,024.
What this means in practice: small agents — the kind builders ship in production, with a 1,500-token system prompt and a 2,000-token tool registry — were previously sub-threshold for cache. Every turn paid the full input price. Now they fall inside the cache window and get the 10× cache-hit discount on every input token after the first call.
Cache-hit pricing on Opus 4.8 is $0.50 / 1M input (90% off the $5 list rate). On a typical agent loop that re-sends 3,500 tokens of system + tools + memory at each turn, that’s the difference between $0.0175 per turn (no cache) and $0.00175 per turn (cache hit) — 10× cheaper, on every turn after the first.
This brings Claude Opus into the same cache-economics conversation that Reasonix has been making about DeepSeek V4 Pro (99.82% cache hit, $12 instead of $61 for 435M tokens). Anthropic is not at DeepSeek’s $0.003625 / 1M cache rate, but the threshold drop is the door opening.
What to do this week: if you have an Opus-based agent with a system prompt between 1,024 and 4,096 tokens, you just got 10× cheaper input. Audit your agents, count tokens, switch to 4.8, watch your bill drop. If your system prompt was already over 4,096 tokens, this changes nothing for you — keep going.
Test your cache hits in 30 seconds
Concrete check: hit the Messages API twice with the same input, watch the cache_creation_input_tokens and cache_read_input_tokens fields in the response.
# First call — creates the cache entry
curl -s https://api.anthropic.com/v1/messages \
-H "x-api-key: $ANTHROPIC_API_KEY" \
-H "anthropic-version: 2023-06-01" \
-H "content-type: application/json" \
-d '{
"model": "claude-opus-4-8",
"max_tokens": 50,
"system": [
{
"type": "text",
"text": "<your 1200+ token system prompt here>",
"cache_control": {"type": "ephemeral"}
}
],
"messages": [{"role": "user", "content": "hello"}]
}' | jq '.usage'
# Run the same call again within 5 minutes — should show cache_read_input_tokensIf cache_read_input_tokens is greater than 0 on the second call, you’re inside the cache window. If it’s 0, your prompt is either under 1,024 tokens or the cache TTL (default 5 minutes) expired. Bump your system prompt size, or use the longer-TTL cache_control extended beta.
2. Fast mode is now 3× cheaper — real-time agents become economically viable
Opus 4.7’s fast mode was $30 / $150 per million tokens — 6× the base rate. That priced it out of any production use that wasn’t a small enterprise demo.
Opus 4.8 fast mode is $10 / $50 per million. Still 2× the base rate, but a 3× drop from 4.7. (Source: Anthropic announcement and Simon Willison’s review)
Fast mode runs at 2.5× the speed of standard Opus 4.8. So for real-time products — voice agents, live customer support, in-IDE auto-complete with reasoning — fast mode used to be aspirational and is now a viable production tier.
The catch: fast mode is still gated to organizations in the research preview. “Contact your account manager to request access,” per the announcement. If you’re an enterprise customer building anything real-time, this is now the call to make.
What to do this week: if you previously evaluated Opus fast mode and decided the unit economics didn’t work, re-run those numbers. A 3× price cut at the same latency profile is a different product.
3. Mid-conversation system messages preserve the cache — the API change nobody is talking about
The Messages API now accepts role: "system" entries inside the messages array, immediately after a user turn. Subject to placement rules.
Why this matters: previously, the only way to update Claude’s instructions during a long-running agent loop was to rewrite the system prompt at the top of the messages array. Rewriting the top means breaking the prompt cache. Breaking the cache means paying full input price on every subsequent turn.
With mid-conversation system messages, you append the new instruction ("Permissions just changed: you may now write to /etc", or "Token budget halved, prioritize concise output") as a system role entry deeper in the conversation. The earlier turns stay in cache. The new instruction takes effect immediately.
Simon Willison flagged this as “really powerful” in his review — and noted he had to check his own LLM library design to confirm it would handle mid-conversation system entries correctly.
What to do this week: if you maintain an agent harness, audit your “update permissions / update environment / update token budget” hot paths. Anywhere you currently rewrite the system prompt, you can now append a system message instead. Test for cache-hit preservation on the next 3-5 turns to verify.
This is the kind of feature that doesn’t show up in benchmark tables but reshapes how production agents are written. (Compare with the Reasonix-style cache-first agent design — same architectural pressure, different vendor.)
4. Dynamic Workflows + parallel subagents = real codebase-scale migrations in Claude Code
This is the headline feature for Claude Code users.
Dynamic Workflows is in research preview. It lets Claude plan a large task, spawn hundreds of parallel subagents in a single session, and verify its outputs before reporting back. The Anthropic example: “codebase-scale migrations across hundreds of thousands of lines of code from kickoff to merge, with the existing test suite as its bar.”
Availability: Claude Code for Enterprise, Team, and Max plans only.
This is the natural evolution of the multi-agent code-review pattern we wrote about in Use AI to write better code, more slowly — except instead of 4-7 subagents reviewing each other, it’s hundreds of subagents executing different slices of the same migration in parallel.
The constraint that makes this work — and that builders need to internalize — is the verification step. Claude Code runs the existing test suite as its bar. If you don’t have tests, Dynamic Workflows has nothing to verify against, and the feature degrades to “claude produced a giant unreviewed diff.” This is the same finding as the EURECOM Constraint Decay paper: coding agents perform fine on prototypes (no constraints) and fail on production backends (database + ORM + architecture constraints). Dynamic Workflows shifts the bottleneck from “can the agent code?” to “is your test suite a real constraint?”
What to do this week: if you’ve been postponing a “rip out library X, replace with Y” migration because the LOC count was scary, this is the feature you’ve been waiting for. Two pre-conditions: (1) you have a real test suite that covers the affected paths, and (2) you’re on Claude Code Enterprise / Team / Max. If you fail either, wait. If both, this is the week to plan the migration.
Effort levels: which one to use when
Opus 4.8 defaults to high effort. The slider exposes three steps beyond that:
| Level | When Anthropic recommends it | Token cost vs default | Use for |
|---|---|---|---|
| high (default) | balanced quality + latency | baseline | most coding, most agent loops, most chat |
| extra (“xhigh” in Claude Code) | difficult tasks, long-running async | higher | architecture decisions, complex refactors, deep research that runs in background |
| max | hardest problems, no time pressure | highest | one-shot evaluations, research-level reasoning, when you’d otherwise call multiple models and vote |
The honest answer for most builders: stay on high for production agent loops. The cost-quality curve flattens fast after high. The one place to push to extra is when you’ve already isolated a hard sub-step (the “this PR migration plan” turn, the “decide which library to swap to” turn) — not the whole conversation.
On Claude Code specifically: switching from default to xhigh for the planning turn of a multi-step task and back to default for the execution turns is a clean pattern. The plan benefits from more thought; the execution doesn’t.
What did NOT change
The benchmark gains are real but modest. Anthropic itself frames Opus 4.8 as “a modest but tangible improvement.” Highlighting the customer quotes is the giveaway — when a release is incremental, you lean on quotes; when it’s a leap, the benchmark numbers carry the post. (Source: Simon Willison’s review, who also flagged this framing as “refreshing.”)
What did not change between Opus 4.7 and 4.8, but matters:
- Knowledge cutoff: January 2026. Same as 4.7. If you were waiting for a cutoff bump for fresher training data, this isn’t it.
- Context window: 1,000,000 tokens. Same as 4.7.
- Max output: 128,000 tokens. Same as 4.7.
- Base pricing: $5 input / $25 output per million tokens. Same as Opus 4.5, 4.6, 4.7, and now 4.8 — Anthropic has held the line for four releases.
- Pelicans on bicycles. Simon’s eval is still the eval. The pelican looks marginally better at high effort. We are all becoming pelican connoisseurs.
The honesty improvement is the durable win
The most interesting metric Anthropic published: Opus 4.8 is 4× less likely than Opus 4.7 to allow flaws in code it has written to pass unremarked.
In production agent terms: you ship less broken code. Or more precisely, when Opus 4.8 ships broken code, it is 4× more likely to flag the broken part itself rather than confidently claim success.
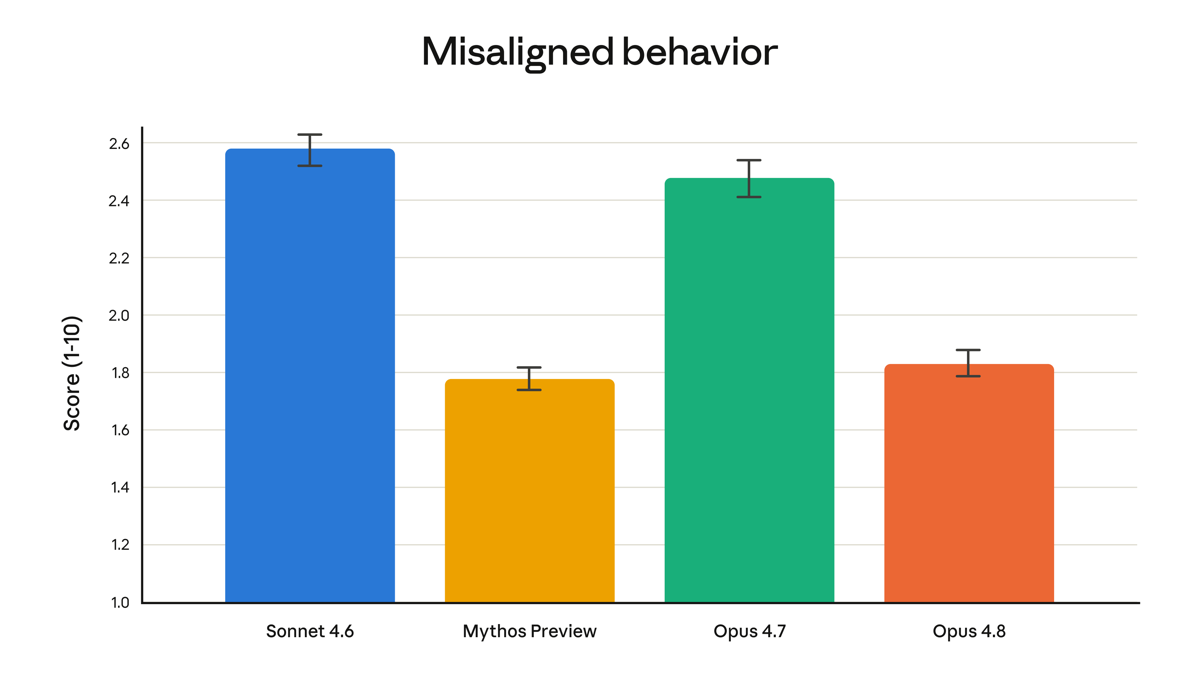
Anthropic’s own misaligned-behavior eval (lower is better): Opus 4.8 (~1.83) is a clear drop from Opus 4.7 (~2.48), and the second-best of the four models shown. This is the safety story the benchmark tables don’t capture. (Source: Anthropic announcement)
This is the kind of metric that doesn’t move benchmark dashboards but moves production reliability. Combined with the system-card finding that Opus 4.8 “had the lowest incorrect-rate of the six models on every benchmark — achieved mainly by abstaining on questions about which it was uncertain rather than by answering more questions correctly,” this is a model that learned to say “I don’t know” and “I might be wrong.”
Compare this with the framing in Anthropic and OpenAI just found product-market fit — the PMF is in coding agents, and coding agents are gated on hallucination cost. A 4× drop in unflagged code flaws is a 4× drop in the worst-case cost of running an autonomous coding agent.
What changes for you depends on where you use Claude
The four shifts above don’t land equally across surfaces:
| Surface | What changes today | What you should do |
|---|---|---|
| Anthropic Messages API direct | Lower cache minimum, mid-conv system messages, fast mode if eligible | Audit token counts; switch model ID; test cache hits with the curl above |
| Claude Code (auto model) | Already on 4.8; Dynamic Workflows on Enterprise/Team/Max | Plan one big migration; verify your tests cover the diff zone |
| Claude Code (pinned model) | Nothing until you re-pin | claude update, then /model → Opus 4.8 (or pin claude-opus-4-8) |
| claude.ai chat | Effort slider appears in UI; 4.8 selectable | Default to high; bump to extra only on hard turns |
| Cowork | Effort slider; better long-session collaboration per testers | Try the same prompt at high vs extra to feel the curve |
| 3rd-party wrappers (LangChain / LlamaIndex / Cursor / Cline) | Depends on SDK update | Check release notes; older SDKs reject mid-conv system messages |
If you’re a solo builder shipping a small Opus-backed product, the cache minimum drop is the change you can monetize this week. If you’re at an enterprise on Team/Max, Dynamic Workflows is the change to plan a project around.
How to migrate from Opus 4.7 to 4.8
Steps:
- API users: swap the model ID. The new ID is
claude-opus-4-8(dashes, not a dot —claude-opus-4.8will fail). No other code change needed for basic invocations. - Claude Code users on
automodel selection: you’re already on 4.8 as of the release. - Claude Code users on pinned model: run
claude updateto get v2.1.154+, then/modeland pick Opus 4.8 — or pinclaude-opus-4-8in your settings instead ofclaude-opus-4-7. (Full walkthrough: How to switch to Claude Opus 4.8 in Claude Code, claude.ai, and the API.) - If you use prompt caching: re-check your minimum prompt length. If it was below 4,096 tokens, you may now be inside the cache window without changing anything. If it was below 1,024, you’re still sub-threshold.
- If you use mid-conversation
systementries (new feature): make sure you’re on the latest Anthropic Python SDK or compatible TypeScript SDK. Older SDKs reject the new message shape. - If you’re on Enterprise/Team/Max and want Dynamic Workflows: opt into the research preview from your Claude Code settings.
Sources
- Introducing Claude Opus 4.8 — Anthropic
- Claude Opus 4.8: “a modest but tangible improvement” — Simon Willison
- llm-anthropic 0.25.1 — Simon Willison
- What’s new in Claude Opus 4.8 — Anthropic docs
- Internal reference: Reasonix DeepSeek cache economics, Constraint Decay in LLM coding agents, AI writes better code more slowly, Anthropic + OpenAI PMF