Gemma 4 QAT: Google's quantization-aware checkpoints cut Gemma 4's memory again — E2B now fits in 1GB
On June 5, 2026, Google released quantization-aware-training (QAT) checkpoints for the whole Gemma 4 family. QAT bakes quantization into training, so a 4-bit model keeps more quality than a normal post-training quant — and a new mobile format shrinks Gemma 4 E2B to about 1GB. Here's what changes for builders running Gemma locally.
Two days after shipping the laptop-grade Gemma 4 12B, Google released quantization-aware-training (QAT) checkpoints for the entire Gemma 4 family on June 5, 2026. (Source: Google, 2026-06-05) The point for builders: the same models you can already run locally now keep more of their quality when squeezed to 4-bit — and the smallest one fits in about 1GB.
Key facts:
- QAT checkpoints ship for five sizes: Gemma 4 E2B, E4B, 12B, 26B A4B, and 31B. (Source: Google, 2026-06-05)
- QAT bakes quantization into training instead of applying it afterward. Google’s claim: “our QAT results yield even higher overall quality compared to standard PTQ baselines.” (Source: Google, 2026-06-05)
- The release includes the popular Q4_0 format plus a new mobile format that drops Gemma 4 E2B to about 1GB of memory. (Source: Google, 2026-06-05)
- Weights are on Hugging Face (e.g.
google/gemma-4-12B-it-qat-q4_0-unquantized), with support across llama.cpp, Ollama, LM Studio, vLLM, MLX, and LiteRT-LM. (Source: Google, 2026-06-05) - Google did not publish QAT benchmark scores in the announcement — the quality claim is stated, not numbered. (Source: MarkTechPost, 2026-06-05)
Why quantization-aware training matters
Most local models you download are post-training quantized (PTQ): the model is trained at full precision, then compressed to 4-bit afterward. That compression always costs some quality. QAT instead simulates the 4-bit rounding during training, so the weights settle into values that survive quantization — you get a 4-bit file that behaves closer to the full-precision model.
There’s a precedent worth knowing: on the previous generation, Gemma 3 QAT cut the Q4_0 perplexity drop by 54% in llama.cpp evaluation. (Source: MarkTechPost, 2026-06-05) That’s the kind of gap QAT closes — same file size, noticeably less degradation.
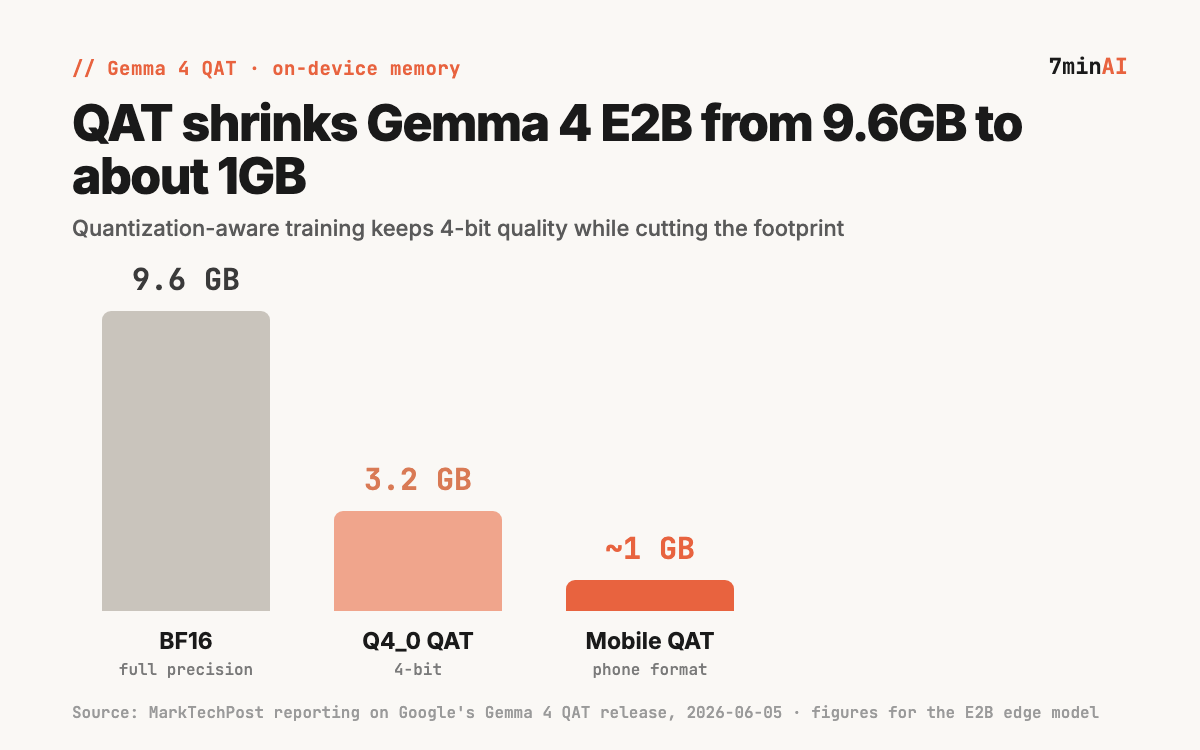
According to MarkTechPost’s reporting, the memory picture for the smallest edge model looks like this: E2B in BF16 is ~9.6GB, the Q4_0 QAT version is ~3.2GB, and the mobile QAT format is ~1GB. (Source: MarkTechPost, 2026-06-05) Google did not break out the per-size numbers for 12B/26B/31B in the announcement.
What this changes if you run Gemma locally
If you already pulled a community 4-bit GGUF of Gemma 4, the QAT checkpoint is a near drop-in upgrade: same memory budget, better output. For the 12B model that this site’s Gemma 4 local setup guide walks through, that means the Q4_0 path now has an official, quality-optimized source rather than only community quants.
The mobile format is the more interesting story long-term. A 1GB multimodal-capable model is small enough to ship inside a phone app and run fully offline — the same on-device, no-cloud-bill argument that made the original Gemma 4 12B notable, pushed down to hardware most people carry in a pocket.
One honest caveat: because Google published the quality claim without benchmark numbers, validate the QAT checkpoint against your own task before assuming it matches the full model. The historical Gemma 3 result is encouraging, but “higher quality than PTQ” is a relative claim, not an absolute one.
Sources
- Gemma 4 with quantization-aware training — Google (The Keyword), 2026-06-05
- Google DeepMind Releases Gemma 4 QAT Checkpoints: Q4_0 and a New Mobile Format Cut On-Device Memory — MarkTechPost, 2026-06-05
- Gemma 4 QAT — How to Run Locally — Unsloth Documentation, 2026-06-05
Source: Google (The Keyword)