Mistral ships Vibe remote agents on Mistral Medium 3.5 — cloud coding agents at $1.5/$7.5 per 1M tokens
At its first AI Now Summit (Paris, May 28, 2026), Mistral launched Vibe — cloud coding agents that run async and open PRs — powered by Mistral Medium 3.5, a 128B dense model with a 256k context that scores 77.6% on SWE-Bench Verified at one-tenth the price of frontier US models.
Mistral used its first AI Now Summit (Paris, May 28, 2026) to ship Vibe — a unified agent platform that takes coding work “from request to merged change, across the web app, your editor, and your terminal” (Source: Mistral AI Now Summit). The headline builder feature is Vibe remote agents: cloud agents that run asynchronously, in parallel, and open reviewable pull requests on their own. They are powered by a new model, Mistral Medium 3.5.
Key facts:
- Mistral Medium 3.5 is a 128B dense model with a 256k-token context window, in public preview under a modified MIT license. (Source: Mistral AI)
- API pricing is $1.5 per 1M input tokens and $7.5 per 1M output tokens.
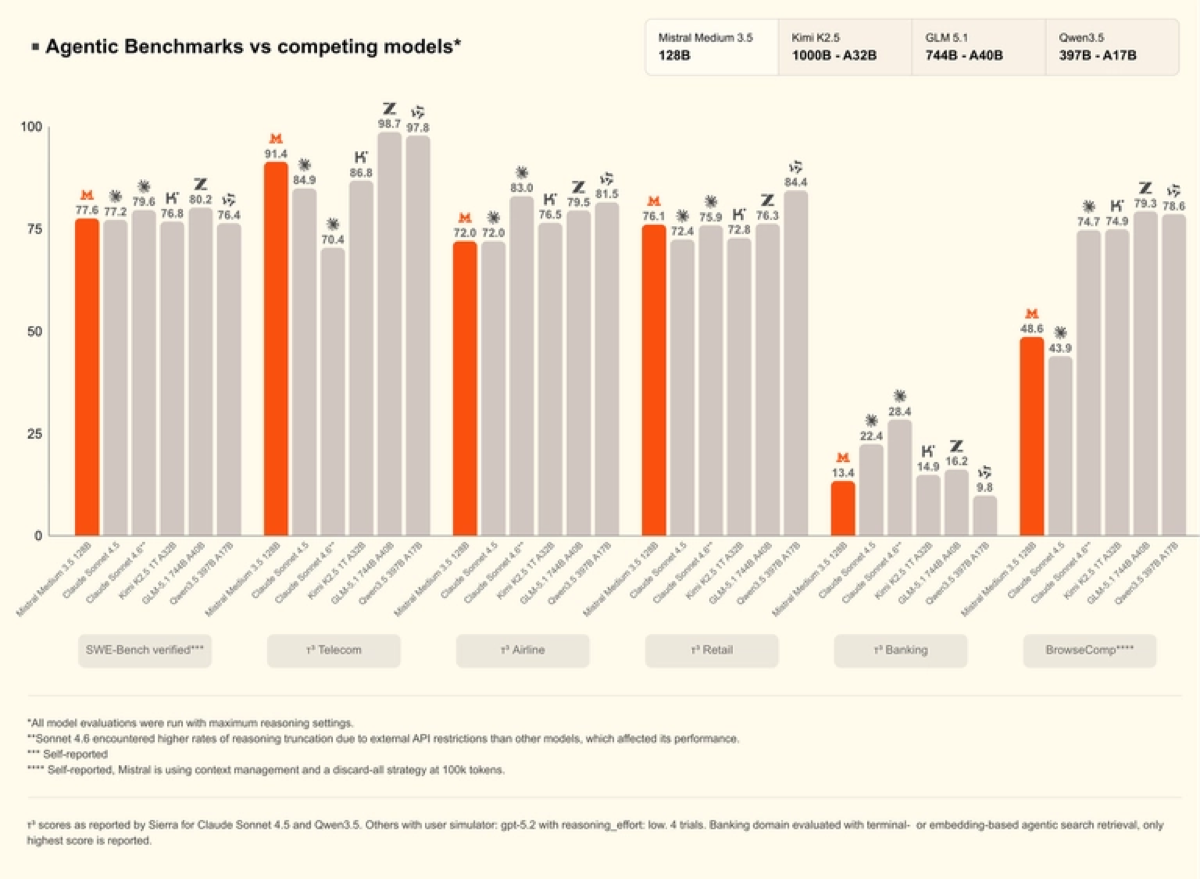
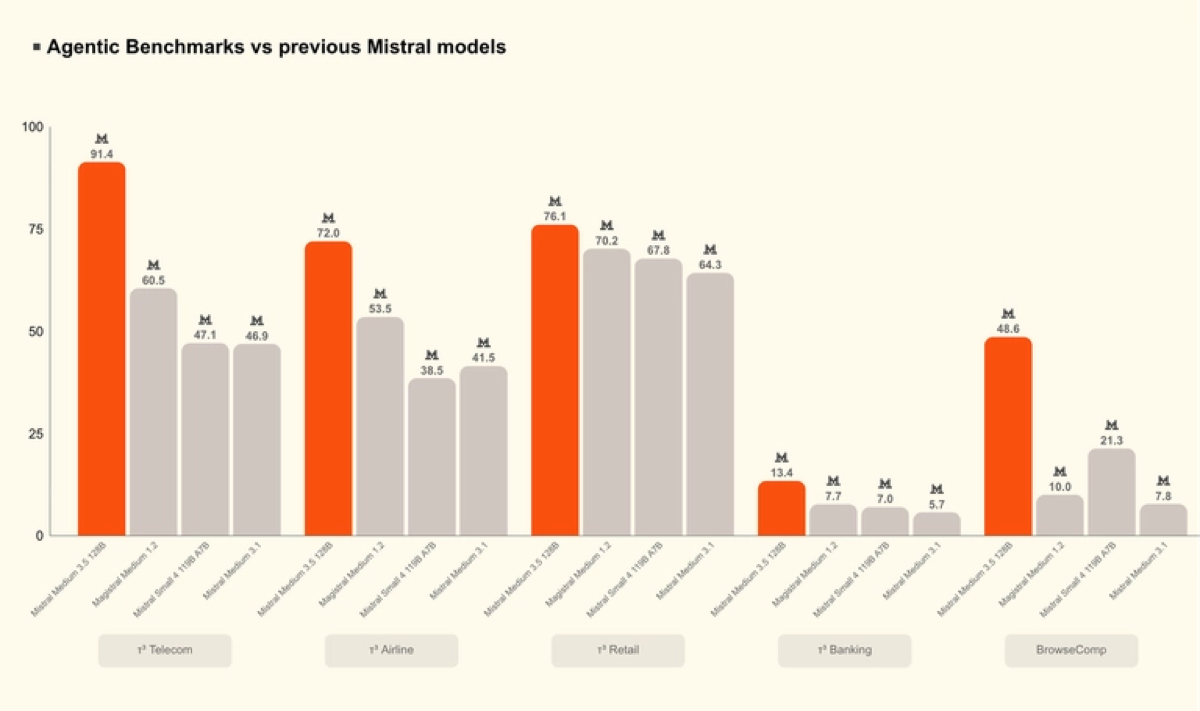
- It scores 77.6% on SWE-Bench Verified and 91.4 on the τ³-Telecom agentic benchmark, per Mistral’s own numbers.
- Remote agents integrate with GitHub, Linear, Jira, Sentry, Slack, and Teams, and can “teleport” a local CLI session to the cloud with history intact.
- Vibe is available on Pro, Team, and Enterprise plans.
What this means if you’re building with coding agents
Vibe remote agents drop into the same slot as Cursor’s background agents, Claude Code, and OpenAI’s Codex — fire off a task, walk away, review a PR later. The differentiator is price-per-capability. At $1.5 / $7.5 per 1M tokens, Mistral Medium 3.5 is roughly an order of magnitude cheaper than frontier US models on output tokens, while landing a 77.6% SWE-Bench Verified score that sits in competitive territory rather than at the top.
The honest read: the headline benchmarks are self-reported, and the footnotes are doing work. Mistral applies its own context-management and “discard-all at 100k tokens” strategy on the agentic suites, and several competitor numbers ran under constrained settings. Treat 77.6% as “competitive, verify on your repo” — not “beats Opus.” For a frame on how a cheaper cloud tier changes agent economics, see our Cursor Composer 2.5 guide and the Reasonix cache-engineered coding agent writeup.
The strategic context: multiple outlets (VentureBeat, Futurum, meshedsociety) report Vibe is a rebrand of Le Chat into a single agent spanning productivity and software development, alongside a full-stack “Mistral for Industrial Engineering” push with Airbus, BMW Group, and ASML, and a new 10 MW inference data center near Paris. For EU teams with data-residency constraints, a frontier-adjacent coding agent hosted in France — at one-tenth the output price — is a genuinely new option. The catch worth watching: no published per-task cost ceiling on remote agents, so a runaway agent loop is on your bill.
What’s still unclear
- VS Code / IDE specifics: Mistral describes “Vibe for Code” across terminal, IDE, and background, but hasn’t published the exact extension/setup details.
- Independent benchmarks: all coding scores are self-reported; no third-party SWE-Bench Verified run yet.
- Rate limits on remote agents: parallelism is advertised but concurrency caps per plan aren’t documented.
Sources
- Vibe remote agents + Mistral Medium 3.5 — official model specs, pricing, benchmarks
- Mistral AI Now Summit 2026 — Vibe “request to merged change” coding workflow, industrial partnerships
- VentureBeat: Mistral launches Vibe, expands into industrial AI — Le Chat→Vibe rebrand, Paris data center
- Futurum: Mistral shifts to full-stack strategy with Vibe — strategy + revenue target context
Source: Mistral AI