Claude Fable 5 lands at $10/$50 and tops SWE-Bench Pro at 80.3%
Anthropic shipped Claude Fable 5 on June 9, 2026 — a frontier coding model with a 1M-token context that scores 80.3% on SWE-Bench Pro versus 58.6% for GPT-5.5. It's the production-safeguarded twin of the restricted Mythos 5, priced at $10/$50 per million tokens. Here's what it means if you build with Claude Code.
Anthropic released Claude Fable 5 on June 9, 2026 — its new frontier model, aimed squarely at long-horizon agentic coding. (Source: Anthropic, 2026-06-09) For builders, the headline isn’t just the benchmark lead; it’s that Fable 5 is the generally available, production-safeguarded deployment of the same weights as Claude Mythos 5, which stays locked to a small trusted-access program.
Key facts:
- The API model string is
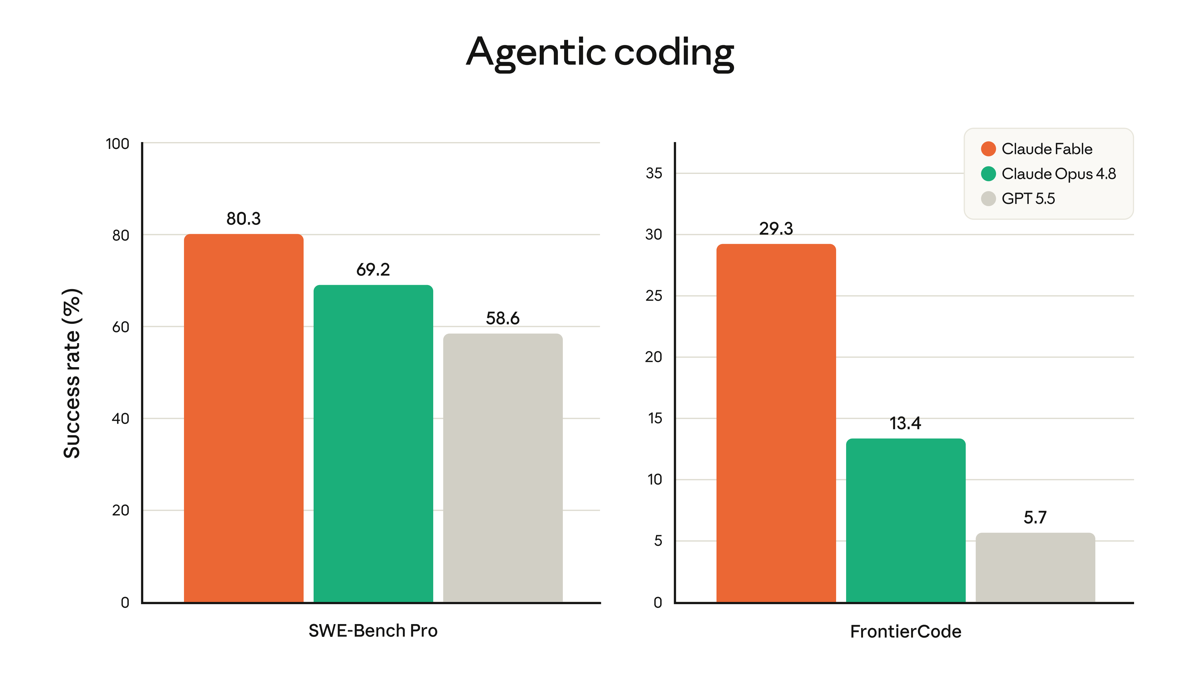
claude-fable-5. It went live everywhere on June 9, 2026. - It scores 80.3% on SWE-Bench Pro. Claude Opus 4.8 scores 69.2% and GPT-5.5 scores 58.6% on Anthropic’s own table.
- Input is priced at $10 per million tokens; output at $50 per million. Anthropic notes that’s less than half the price of Claude Mythos Preview.
- The context window is 1 million tokens in, up to 128K out. It takes text and image input.
- On Terminal-Bench 2.1 it scores 88.0% and on FrontierCode Diamond 29.3% (vs 13.4% for Opus 4.8).
- Fable 5 is the safeguarded twin of the restricted Mythos 5 — same weights, with production classifiers bolted on.
What this means if you build with Claude Code
Fable 5 is now the strongest coding model in the Claude lineup, so if you drive Claude Code as a daily driver, it becomes the model to reach for on multi-step, long-running tasks. Anthropic cites Stripe CEO Michael Truell saying Fable 5 “compressed months of engineering into days” on a 50-million-line Ruby migration, and GitHub CPO Mario Rodriguez crediting it with “a level of autonomy and reliability that exceeded previous benchmarks.” (Source: Anthropic, 2026-06-09) Treat vendor quotes as marketing, but the SWE-Bench Pro gap over Claude Opus 4.8 — 80.3% vs 69.2% — is measured on the same eval.
The pricing math matters too. At $10/$50, Fable 5 costs more per token than Opus 4.8, so it isn’t a blanket replacement — reserve it for the hard, agentic runs and keep cheaper models for routine edits. On consumption plans it’s billed from day one; on Pro, Max, Team, and Enterprise it’s included at no cost from June 9–22, after which it draws on usage credits.
The catch: it won’t do offensive cyber work
Fable 5 ships with three classifier-based safeguards — cybersecurity, biology/chemistry, and distillation — that trigger on under 5% of sessions on average. The cyber classifier is the one builders will notice: on offensive-security tasks, Fable 5 falls back to Claude Opus 4.8 rather than answering directly.
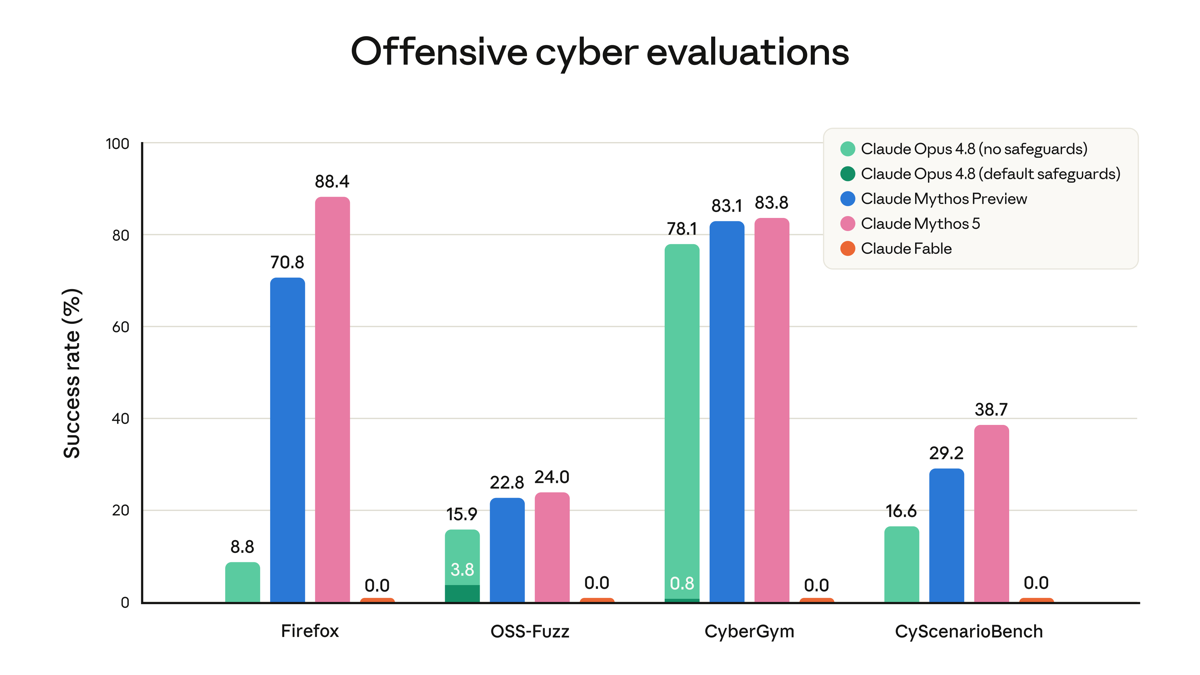
That’s why the chart above shows Fable at zero on all four cyber evals: it isn’t weaker there, it just declines and hands off. Mythos-class models also carry a 30-day data-retention requirement, and that data is not used for training. If your work touches security tooling, expect the handoff — and if you’re comparing coding agents head-to-head, our Claude Code vs Codex and DeepSeek V4 Pro write-ups are the natural next reads.
Sources
- Claude Fable 5 and Claude Mythos 5 — Anthropic, 2026-06-09
- Claude Fable 5: API, Benchmarks, Pricing & How to Use It — TrueFoundry, 2026-06
- Claude Fable 5: Review, Benchmarks and Pricing — LLM-Stats, 2026-06
Source: Anthropic