7 Minutes to Master DeepSeek V4 Pro — The 75% Permanent Price Cut Changes the Agent Math
Last updated: May 23, 2026. Read time: 9 minutes. What you’ll learn: What DeepSeek V4 Pro is, the exact post-discount pricing (with the cache-hit footnote that changes everything), how to call it via API in 5 lines, how to switch to Expert mode in chat.deepseek.com, how it compares to Claude Haiku 4.5 / Gemini 3.5 Flash / Qwen 3.7-Max on cost, and when it actually wins (and when you should still pay 3-10× more for a frontier model).
On May 22, 2026, DeepSeek tweeted a 23-word announcement that quietly reset the cost floor for production agent workloads: the 75% discount on DeepSeek V4 Pro is now permanent.
The full V4 Pro pricing — confirmed on the official DeepSeek API docs — is:
- Input (cache miss): $0.435 / 1M tokens
- Input (cache hit): $0.003625 / 1M tokens
- Output: $0.87 / 1M tokens
- Context window: 1M tokens
- Max output: 384K tokens
For a builder paying for a coding agent: that’s roughly half of Claude Haiku 4.5 output, and about 1/10 of Gemini 3.5 Flash output. If your agent burns 10M output tokens a day, the gap is on the order of $70/day saved vs Claude Haiku, $80/day saved vs Gemini 3.5 Flash, before cache-hit discounts kick in.
This article walks through exactly what V4 Pro is, how to use it, and where the new cost math holds vs falls apart.
1. What V4 Pro actually is
DeepSeek’s V4 family ships as two models with the same architecture but different sizes and rate limits:
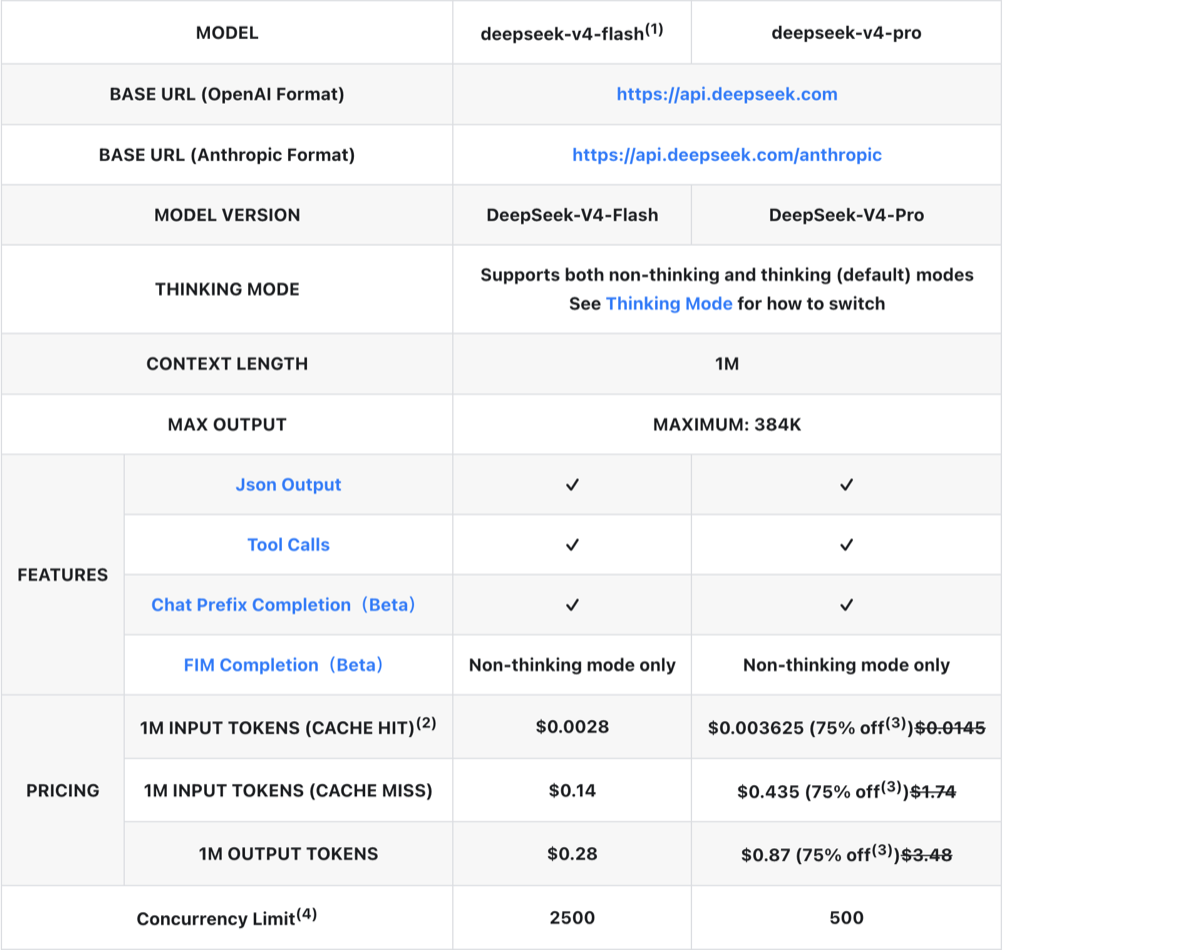
The shape of the two SKUs:
| deepseek-v4-pro | deepseek-v4-flash | |
|---|---|---|
| Context | 1M tokens | 1M tokens |
| Max output | 384K tokens | 384K tokens |
| Input cache miss | $0.435 / 1M | $0.14 / 1M |
| Input cache hit | $0.003625 / 1M | $0.0028 / 1M |
| Output | $0.87 / 1M | $0.28 / 1M |
| Concurrency limit | 500 | 2500 |
| Thinking mode | Yes (default + non-thinking) | Yes (default + non-thinking) |
| JSON / Tool Calls / Chat Prefix | ✓ | ✓ |
| FIM Completion (Beta) | non-thinking only | non-thinking only |
V4 Pro is the deeper-reasoning, slower, more expensive sibling. V4 Flash is the speed/scale variant — when you need 2500 concurrent requests instead of 500, or when output cost is the dominant factor.
Both expose the same OpenAI-compatible and Anthropic-compatible APIs, so swapping models is a one-line change.
2. The actual price impact, in builder terms
Headline numbers don’t translate into anything until you put them next to what you’re already paying. Here’s V4 Pro at the post-permanent-discount rate vs the other agent-tier models I’ve covered on this site:
| Model | Input ($/M) | Output ($/M) | Cache-hit input ($/M) |
|---|---|---|---|
| DeepSeek V4 Pro | $0.435 | $0.87 | $0.003625 |
| DeepSeek V4 Flash | $0.14 | $0.28 | $0.0028 |
| Claude Haiku 4.5 | ~$1.00 | ~$5.00 | (separate prompt-cache pricing) |
| Gemini 3.5 Flash | ~$1.50 | ~$9.00 | (Vertex AI prompt cache discount) |
| Qwen 3.7-Max | ~$2.50 (preview projected) | (not yet GA) | n/a |
A few takeaways before you run the math yourself:
- DeepSeek V4 Pro output is ~5.7× cheaper than Claude Haiku 4.5 output. For an output-heavy workload (code generation, long-form drafting, large summarization batches), this is the most important number on the table.
- V4 Pro input cache-hit at $0.003625 / 1M is essentially free. A 100K-token system prompt repeated 10K times a day costs roughly $3.60 instead of $43.50 vs cache-miss. If your agent loop reuses a long system prompt — which most do — you should be designing around cache hits.
- V4 Flash is even cheaper, but only when output dominates input. V4 Pro becomes worthwhile when you need deeper reasoning per request and can absorb the 3× cost gap vs V4 Flash on output.
These rates are confirmed on the DeepSeek API pricing page as of May 23 2026. Don’t take third-party rate aggregators at face value — DeepSeek has cut prices three times in the last 18 months, and outdated numbers float around for weeks afterwards.
3. How to actually call it — 5-line API example
If you’ve used the OpenAI Python SDK before, the only thing that changes is base_url and the model ID:
from openai import OpenAI
client = OpenAI(
api_key="sk-deepseek-xxx", # from platform.deepseek.com/api_keys
base_url="https://api.deepseek.com", # OpenAI-compatible endpoint
)
response = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[
{"role": "system", "content": "You are a senior backend engineer."},
{"role": "user", "content": "Sketch a Python decorator that retries 3 times with exponential backoff on requests.exceptions.ConnectionError."},
],
)
print(response.choices[0].message.content)If you’re on the Anthropic SDK already (Claude code, etc.), the alternative endpoint is https://api.deepseek.com/anthropic — same drop-in shape.
For a streaming agent loop, change chat.completions.create(...) to chat.completions.create(..., stream=True) and iterate over response. The OpenAI SDK contract is identical.
Enabling cache hits
The cache-hit discount only fires when your system prompt and conversation prefix are byte-identical between requests. Practical implementation:
SYSTEM_PROMPT = """You are an agent in a long-running workflow. Tools available: read_file, write_file, run_shell, get_user_input. Always think before acting…""" # keep this string constant across requests
def chat(messages):
return client.chat.completions.create(
model="deepseek-v4-pro",
messages=[{"role": "system", "content": SYSTEM_PROMPT}] + messages,
)DeepSeek’s caching is automatic and transparent — you don’t pass a cache key, you just keep the prompt prefix identical. The API response body has a usage.prompt_cache_hit_tokens field that confirms how many tokens were served from cache. Log it; that’s your free-ness gauge.
4. Using V4 Pro in chat.deepseek.com (no API key needed)
If you want to test it before writing code, the consumer-side chat works:
- Go to https://chat.deepseek.com/
- Sign in (Google / email)
- Default lands on Instant mode. Click the Expert tab to switch:
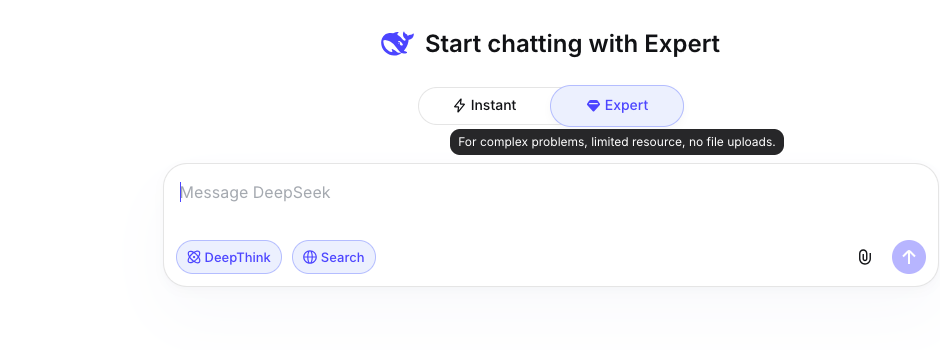
Note the official tooltip: “For complex problems, limited resource, no file uploads.” That tells you three things:
- Expert mode is rate-limited (consumer plan is a fixed daily quota of Pro-tier replies)
- File uploads aren’t supported in Expert (use Instant for PDF / image work)
- The product positions Expert as the deeper-reasoning track — match the API positioning of V4 Pro
The DeepThink and Search toggles in the input bar work in both modes — DeepThink enables visible reasoning trace, Search adds web grounding. Both add latency.
5. The cache-hit math, with a real number
Cache hits are why V4 Pro is so different from V3.5 (the predecessor where input was $0.27 / 1M, no significant cache discount). Let’s do a concrete calculation.
Setup: a coding agent loop where the system prompt is 50K tokens (tool definitions + style guide + project context), and you make 1000 agent steps per day. Each step adds ~5K conversation tokens and produces 2K output tokens.
Without cache discounts (V3.5 era):
- Input per day: (50K + 5K) × 1000 = 55M tokens × $0.27 = $14.85/day
- Output per day: 2K × 1000 = 2M tokens × $1.10 = $2.20/day
- Total: $17.05/day, $511/month
With V4 Pro cache hits (50K system prompt cached after first call):
- Input cache hit: 50K × 999 × $0.003625/M = $0.18
- Input cache miss (first call + 5K new per call): 50K + 5K×1000 = 5.05M × $0.435 = $2.20
- Output: 2M × $0.87 = $1.74
- Total: ~$4.12/day, $124/month
Same agent, ~76% cost reduction. If you’re running multiple agent instances in parallel with the same system prompt, the savings scale further (the cache is shared across requests sharing the same prefix).
This is what “permanent 75% discount” actually means in production: not “all your bills shrink 75%,” but “the long-tail per-step costs of agent loops with stable system prompts drop near zero.”
6. When V4 Pro wins — and when you should still pay 3-10× more
Reach for V4 Pro when:
- Your agent burns large output volumes (code generation, doc generation, long-form drafting) and Haiku-class quality is acceptable
- You can structure your prompts so the prefix is stable across calls (long system prompt + variable user content → cache hits)
- You’re cost-sensitive enough that the 3-10× gap vs Claude/Gemini matters more than the marginal benchmark gap
- You’re already inside the OpenAI SDK ecosystem (zero-friction drop-in via
base_url) - Your workload tolerates 500 concurrent requests (V4 Pro’s hard cap)
Reach for V4 Flash instead when:
- Output dominates input and you can absorb a small quality drop for ~3× cheaper output
- You need 2500 concurrent requests (chat support, voice transcription pipelines, etc.)
- The task is mostly tool-call orchestration where reasoning depth doesn’t matter
Reach for Claude Opus 4.7 / GPT-5 / Gemini 3 Pro instead when:
- The task genuinely needs frontier reasoning (math proofs, novel algorithm design, deep code refactors with unclear constraints)
- The 5-10× cost premium pays for itself in fewer human review iterations
- You can’t tolerate the small quality drop: V4 Pro is competitive on most benchmarks but not consistently at the top
- You need vision input (V4 Pro is text-only)
Reach for Qwen 3.7-Max or open-weight alternatives when:
- You need to self-host eventually — DeepSeek V4 Pro is API-only and not open-weighted; Qwen has a public open-weight cadence you can plan around
- You’re in a regulated environment where data can’t leave a specific jurisdiction
7. Gotchas — what to expect when you actually deploy
After plugging V4 Pro into a real agent loop, these are the practical things that aren’t in the docs:
- Cache hits aren’t free if your prefix drifts. A common bug: someone adds a per-request
datetime.now()to the system prompt for “freshness.” That single line invalidates the cache on every call. Audit your system prompt construction for any dynamic content. - Cache only persists for tens of minutes. If your agent is idle for an hour and you fire a new request, the cache is gone. For burst workloads, batch your requests to keep the cache warm.
- Thinking mode is on by default and adds significant latency (5-30s) before the first output token. If your UX can’t tolerate that, pass
extra_body={"thinking": False}(Anthropic endpoint) or use the non-thinking-mode-only endpoint variant. - The concurrency limit is real. 500 concurrent V4 Pro requests = 500 inflight, not 500 RPS. If your agent does 10s thinking per request, 500 concurrent ≈ 50 RPS sustained. Plan accordingly.
- API key creation requires a Chinese phone number for some account types. International builders sometimes hit this — workaround is to use a third-party gateway like OpenRouter that resells DeepSeek without the signup friction (small markup).
- The chat.deepseek.com Expert mode is not the same SKU as the API V4 Pro. Expert is a consumer-rate-limited product. Use the API for serious work; use chat for casual exploration.
8. The bigger picture
The permanent 75% cut isn’t isolated. DeepSeek’s whole product strategy is to set the cost floor for “good enough” production AI, then force the frontier providers to either match on price or differentiate harder on quality. This is the same playbook that took GPT-3.5-tier capability from $20/M to roughly free over 18 months.
For builders, the practical takeaway: if your last build-vs-buy decision priced in Claude Haiku 4.5 or Gemini 3.5 Flash, re-run the math. A 5-10× cost cut isn’t a rounding error — it’s the difference between “this is a viable feature” and “we can’t afford to ship it.” And if your project’s economics depended on optimizing prompts to fit in cheap context windows, V4 Pro’s 1M context + near-zero cache-hit input pricing eliminates that constraint entirely.
Related Articles
- Gemini 3.5 Flash vs Claude Haiku 4.5 — the other current agent-tier comparison
- 7 Minutes to Master Qwen 3.7-Max — Alibaba’s agent-frontier alternative
- 7 Minutes to Master Cursor Composer 2.5 — Cursor’s in-house coding model that competes on the same axis
- Qwen 3.7 open-weight watch — if you need self-hosting eventually
Sources
- DeepSeek API Docs — Models & Pricing — the canonical pricing reference (also the source of the table screenshot above)
- DeepSeek on X — May 22 2026 permanent-discount announcement
- The Next Web — DeepSeek cuts V4-Pro prices by 75%
- Hacker News discussion thread — builder reactions and concrete agent-cost examples
- DeepSeek main site — official brand page