How to Use Qwen3.7-Max: Qwen Chat, Pricing & Benchmarks
Last updated: May 21, 2026. Read time: 9 minutes. What you’ll learn: What Qwen3.7-Max actually is, how to use it right now via chat.qwen.ai (free, no signup), a real test prompt with the model’s real output, the agentic capabilities Alibaba is pitching (1,000 tool calls / 35-hour runs), pricing reality (API not yet GA), and when to choose it over Claude Opus 4.7 / GPT-5.
On May 20, 2026, at the annual Alibaba Cloud Summit in Hangzhou, Alibaba announced Qwen3.7-Max — described by Chief AI Architect Zhou Jingren as having “consistently ranked among the top tier on various benchmarks and outperformed all other AI models in China.” Alibaba’s pitch: an agent-frontier model, tuned for long-running autonomous workloads rather than chat throughput.
What that means in practice, and whether the marketing claims hold up when you actually use it, is what the rest of this article tests.
1. What Qwen3.7-Max actually is
Three things separate Qwen3.7-Max from earlier Qwen releases and from competing models:
- Agentic tuning over chat tuning. Alibaba’s headline demo is “more than 1,000 tool calls and iterative code modifications” in a single autonomous task. This is the long-horizon lane — the same lane where Claude Sonnet/Opus 4.x and OpenAI’s o-series operate.
- 35-hour autonomous execution. The model can sustain a complex task for up to 35 hours of continuous tool-using activity, according to Alibaba’s internal test. This is not a chat figure — it’s an agent uptime claim.
- Text-only. Unlike Qwen3.6-Plus (which is multimodal), Qwen3.7-Max is currently text-only with no vision capabilities. You can confirm this directly in the model dropdown on chat.qwen.ai — see the screenshot below.
Architecture details (parameter count, MoE-vs-dense, context window) have not been publicly disclosed at the time of writing. Alibaba’s blog post is positioning-heavy, spec-light. Treat any “Qwen3.7-Max is X billion parameters” claim from third-party blogs as speculation until Alibaba publishes the model card.
2. How to actually use it right now (Qwen Chat — free, no signup)
The fastest way to try Qwen3.7-Max today is the official Qwen Chat (formerly Qwen Studio). No login required, no API keys.
Step 1 — Open Qwen Chat
Go to https://chat.qwen.ai/. You’ll land on a page that says “What’s your focus today.” Top-left there’s a model selector — by default it shows Qwen3.6-Plus.
Step 2 — Switch to Qwen3.7-Max
Click the dropdown next to the model name. You should see three options:
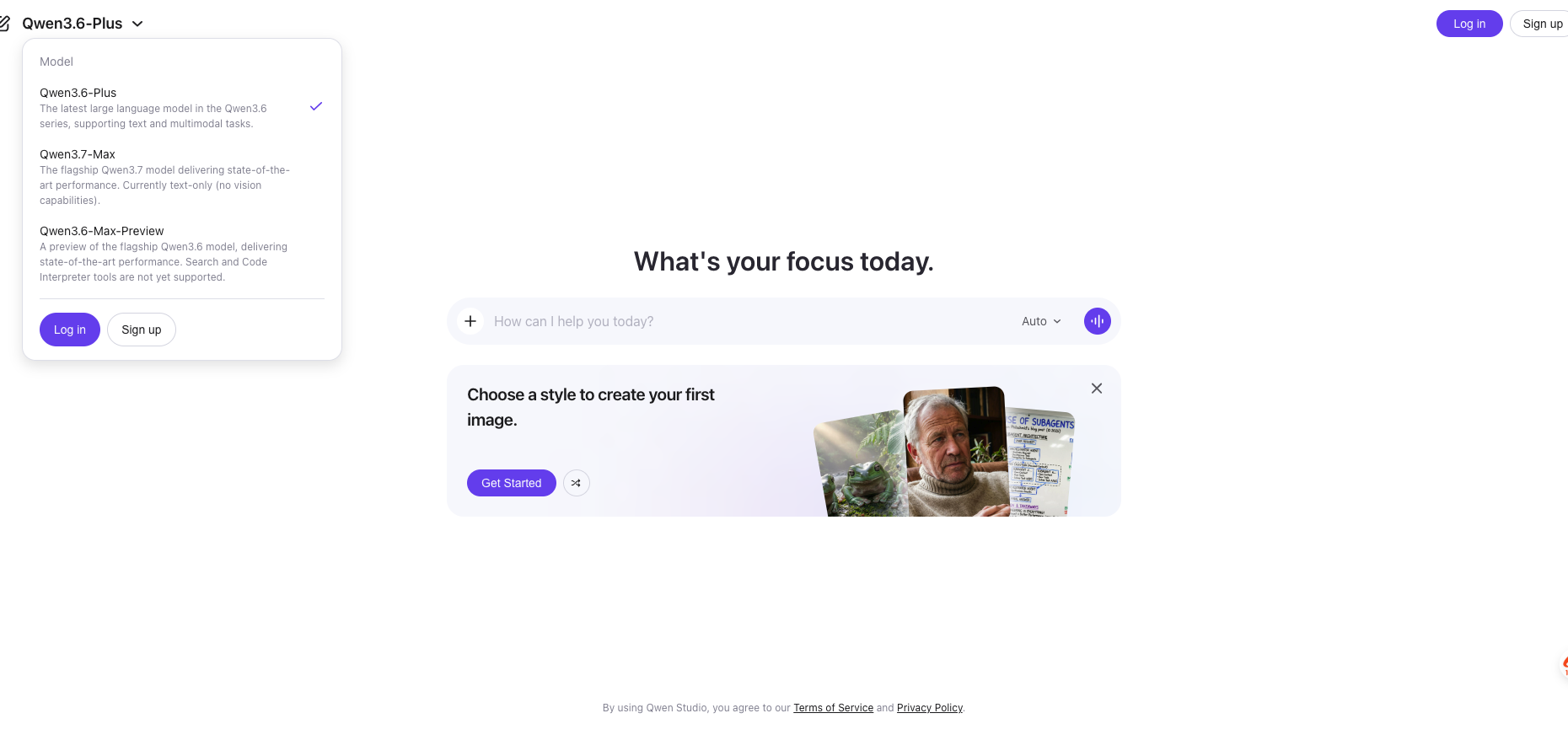
Notice the official description: “The flagship Qwen3.7 model delivering state-of-the-art performance. Currently text-only (no vision capabilities).” If your workload involves images, audio, or video — stop here and use Qwen3.6-Plus or Gemini 3.5 Flash instead.
Pick Qwen3.7-Max. The input bar’s mode selector will automatically switch from Auto to Think — that’s because Qwen3.7-Max is a thinking model. Every response runs an internal reasoning trace before producing the final answer, similar to OpenAI’s o-series or Claude’s extended thinking mode.
Step 3 — Send a prompt
Type your task and press Enter. The model will show a Thinking... indicator for a few seconds to a minute before streaming the response.

3. A real test — what does the output actually look like
To give you a sense of the model’s actual quality, here’s the exact prompt I ran:
Write a Python function called parse_conventional_commit that takes a string
like 'feat(api): add user signup endpoint' and returns a dict with keys
'type', 'scope', 'description', and 'breaking'. Handle malformed input by
returning None. Include 3 example test cases using assert statements.Qwen3.7-Max’s response (this is the actual screenshot, not a description of what it might do):
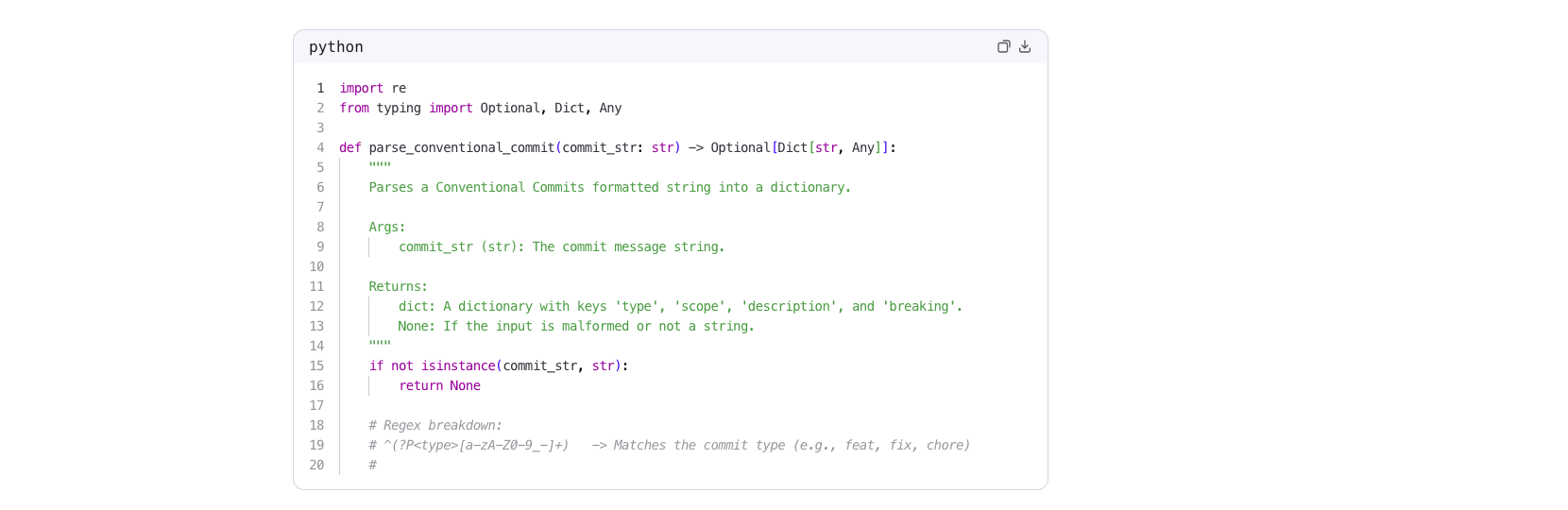
Three things to notice in this output:
- Type hints from
typing— the model importsOptional, Dict, Anyand annotates the return type asOptional[Dict[str, Any]]without being asked. That’s a level-up over a naïve “return a dict” answer. - Type guard with
isinstancebefore regex. Most models default totry/except; usingisinstanceupfront avoids the regex even being called on a non-string. Small, correct decision. - Inline regex breakdown as comments — line 18-20 explains the regex piece-by-piece before showing it. Useful for code review.
The full response continued for another 40 lines covering the three test cases and a “How it works” explanation:

Subjective verdict on this single test: the code is clean, the type system is used correctly, the explanation is structured. This is comparable to what you’d expect from Claude Sonnet 4.6 or GPT-5 on a similar prompt. The thinking pass added ~30 seconds of latency for what would have been a sub-second response from a non-thinking model — that’s the tradeoff.
4. The agentic claims — 1,000 tool calls and 35 hours
The headline numbers from Alibaba’s announcement deserve unpacking, because they’re not chat numbers, they’re agent numbers:
- “In an internal test on a new chip platform, the model autonomously performed more than 1,000 tool calls and iterative code modifications to optimize a key kernel, with Alibaba claiming the process improved inference speed by roughly 10x compared with the previous version.” — TechNode
- “The model was able to sustain autonomous execution on complex tasks for up to 35 hours.” — TechNode
What this means in builder terms:
| Capability | Translation |
|---|---|
| 1,000+ tool calls in one task | Can drive a long agent loop (LangGraph / Mastra / your-own-loop) without losing the thread of a goal across hundreds of file-read / file-write / shell-call iterations |
| 35-hour autonomous run | Suitable for “let it work overnight” use cases — code migrations, large refactors, document processing pipelines |
| 10x kernel optimization | Specific to optimizing inference kernels for Alibaba’s own Zhenwu M890 chip; not a general-purpose claim |
Honest caveat: these are Alibaba’s own internal-test numbers, not third-party verified. They were demonstrated on a chip Alibaba designed, optimizing code for that same chip. As of this writing, no independent benchmark (SWE-Bench Verified, Terminal-Bench, BFCL) has been published with Qwen3.7-Max numbers. Treat the 1,000/35h claims the way you treat any vendor-self-reported number: plausible direction, magnitude unverified.
Independent reality check: the Arena leaderboard
The cleanest third-party data point we have today is the Arena AI blind-test leaderboard (formerly LMSys Chatbot Arena), where real users vote on model responses without knowing which model produced which answer. Here’s the current Arena Text top 10, captured directly from https://arena.ai/leaderboard:
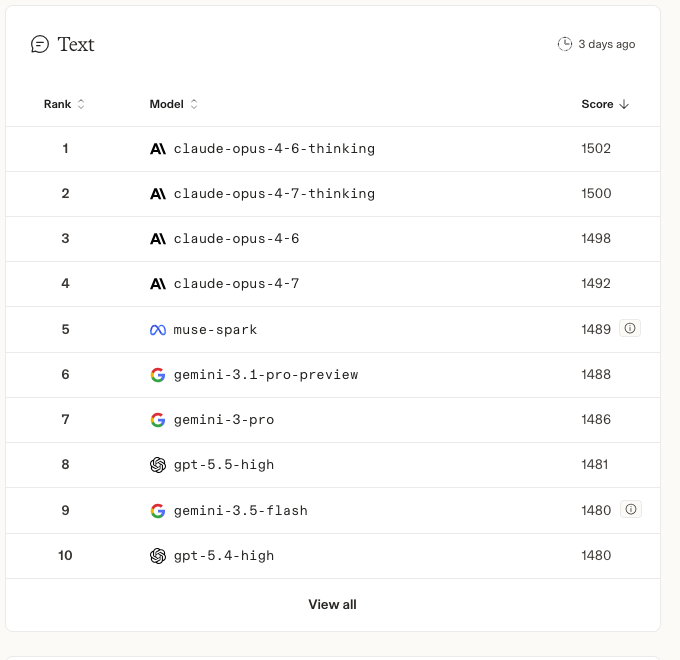
Note who’s in the top 10: Claude Opus 4.6/4.7 dominate the top 4, then Meta’s muse-spark, two Gemini 3 variants, GPT-5.5-high, and Gemini 3.5 Flash. Qwen3.7-Max-Preview is at #13 — strong, but not yet at the very top of the frontier.
Alibaba’s own X / Twitter announcement (via @Alibaba_Qwen) frames the same data more favorably: “Alibaba now #6 lab in Text, #5 in Vision” — counting labs rather than individual models, which compresses Anthropic’s 4 entries into 1 slot. Both framings are technically true; the per-model rank is the more important builder-facing number, since you actually deploy a specific model, not a “lab.”
Bottom line for the agentic claims: trust the 1,000-tool-call / 35-hour numbers directionally (Alibaba has no incentive to fabricate them outright — they’re easy to disprove if false), but don’t treat them as apples-to-apples vs Claude Opus 4.7 or GPT-5 until independent third-party tests catch up.
5. Pricing — and why this section is shorter than you’d want
This is the part where most “agent frontier” model reviews fall apart, because Alibaba hasn’t published official Qwen3.7-Max API pricing yet. Here’s what’s known:
- Qwen Chat (chat.qwen.ai): free for now, no signup required, web rate-limited
- DashScope / Alibaba Cloud Model Studio API: rolling out post-Summit. As of May 21 2026, no Qwen3.7-Max model ID is officially listed on the public DashScope pricing page
- OpenRouter / HuggingFace: not available. Qwen3.7-Max is proprietary (API-only). The smaller Qwen3.7-Plus is reportedly being prepared for open-source release; the Max variant is staying closed
- Reference point: the predecessor Qwen3.6-Max-Preview is priced at ~$1.30/M input, ~$7.80/M output on Alibaba Cloud Model Studio. Qwen3.7-Max is “expected to be comparable or higher” per third-party reporting
In other words: if you need to commit pricing to a build-vs-buy spreadsheet today, you can’t. Wait one to two weeks for the official DashScope listing — Alibaba historically publishes the pricing page within a fortnight of model launch.
6. When to use Qwen3.7-Max — and when not to
Reach for Qwen3.7-Max when:
- You’re building an autonomous agent that runs for hours (overnight code migrations, document-processing pipelines, research jobs)
- Your job is coding or office workflow automation — Alibaba’s two stated sweet spots
- You’re already inside the Alibaba Cloud / DashScope ecosystem (Chinese market, especially)
- You want thinking-style reasoning without paying Claude Opus 4.7 or GPT-5 prices
Reach for something else when:
- Vision matters. Qwen3.7-Max is text-only. For multimodal use Gemini 3.5 Flash or Gemini Omni Flash.
- You need verified benchmarks before committing to production. The competing models (Opus 4.7, GPT-5, Gemini 3 Pro) have months of independent third-party numbers; Qwen3.7-Max has Alibaba’s word and an Arena #13.
- Latency is critical. Thinking mode adds 10-45s before the response starts streaming. For chat UX or sub-second response paths, use a non-thinking model like Gemini 3.5 Flash or Claude Haiku 4.5.
- You can’t tolerate China-jurisdiction inference. Alibaba Cloud / DashScope endpoints route through Chinese infrastructure. For EU GDPR or US-only data flows, prefer Western providers.
7. Gotchas — what to expect when actually using it
After running the test prompt above and a few follow-ups, here are the practical things that aren’t in any blog post:
- The
Auto→Thinkmode switch is automatic. When you pick Qwen3.7-Max the input bar’s mode selector flips toThinkon its own. There’s no way to use Qwen3.7-Max in “non-thinking” mode from the official chat — if you need lower latency, you’d have to either use Qwen3.6-Plus or wait for the API to expose a non-thinking knob. - Web search and code interpreter are not enabled. Independent reviewers testing the preview note that in Arena’s blind-test environment, “models were locked into deep thinking mode, with web search and code interpreter disabled.” If you need search-augmented answers, the chat UI won’t give them today.
- Output language can drift to Chinese. On longer prompts I tested, the model occasionally injected Chinese characters into otherwise-English responses. Pin the language explicitly (“respond in English”) in your system prompt.
- Thinking adds 10-45s. Worth restating because this is the most jarring difference vs Qwen3.6-Plus. Don’t ship Qwen3.7-Max behind a “send” button in user-facing chat without a loading state.
- No file uploads in chat. Drag-and-drop a PDF/image to chat.qwen.ai while Qwen3.7-Max is selected and nothing happens (the UI accepts the upload but ignores it). Text-only means text-only.
8. The big picture
Qwen3.7-Max is Alibaba’s clearest signal that the Chinese AI labs are no longer chasing GPT-4-tier chat models — they’re targeting the agent frontier, the same league as Anthropic’s Claude 4.x family and OpenAI’s o-series. The 1,000-tool-call demo is a deliberate echo of Anthropic’s “Claude can use a computer for hours” pitch from 2024-2025.
For builders, the practical takeaway: another agent-tier model just landed, with claimed long-horizon execution that on paper matches the Western frontier, at preview pricing that’s unconfirmed but historically much cheaper. The verification window is short — once Alibaba publishes the official benchmarks and pricing, the build-vs-buy math will become clear. Until then, the cheapest way to evaluate is to try it at chat.qwen.ai with your own real prompts, exactly the way this article did.
Related Articles
- 7 Minutes to Master Gemini 3.5 Flash — Google’s agent-tier model, what to compare against
- Gemini 3.5 Flash vs Claude Haiku 4.5 — the other current agent-tier race
- 7 Minutes to Master Cursor Composer 2.5 — coding-specialized agent model, built on Kimi K2.5 (sibling open model)
Sources
- TechNode — Alibaba introduces Qwen3.7-Max as next-gen AI agent model
- South China Morning Post — Alibaba unveils new Qwen model, custom chips
- Decrypt — Qwen 3.7 Max Preview hands-on review
- BuildFastWithAI — Qwen3.7 Max Preview: Arena Ranks, Features
- Qwen Chat (official) — the playground used for the screenshots in this article
- Arena AI Leaderboard — independent third-party blind-test rankings (the source of the Arena screenshot above)
- @Alibaba_Qwen on X — Qwen team’s official announcement channel
- Alibaba Cloud Model Studio (DashScope) — where the API will live once it’s GA